


Deep neural networks (DNNs) come in various sizes and structures. The specific architecture selected along with the dataset and learning algorithm used, is known to influence the neural patterns learned. Currently, a major challenge faced in the theory of deep learning is the issue of scalability. Although exact solutions to learning dynamics exist for simpler networks, adjusting even a small part of the network architecture often requires significant changes to the analysis. Moreover, the state-of-the-art models are so complex that they outperform practical analytical solutions. These results consist of complex machine learning models and even the brain, posing challenges for theoretical study.
In this paper, the first related work is Exact solutions in simple architectures, where a lot of progress is made in the theoretical analysis of deep linear neural networks, e.g. the loss landscape is well understood, and exact solutions have been obtained for specific initial conditions. The next related approach is the neural tangent kernel, where a notable exception in terms of universal solutions is that it provides exact solutions applicable to a wide range of models. Next is the Implicit biases in the gradient descent technique, where the investigation of gradient descent is done as a source of generalization performance in DNNs. The final method is Local Elasticity, where a model shows this property if updating one feature vector minimally affects dissimilar feature vectors.
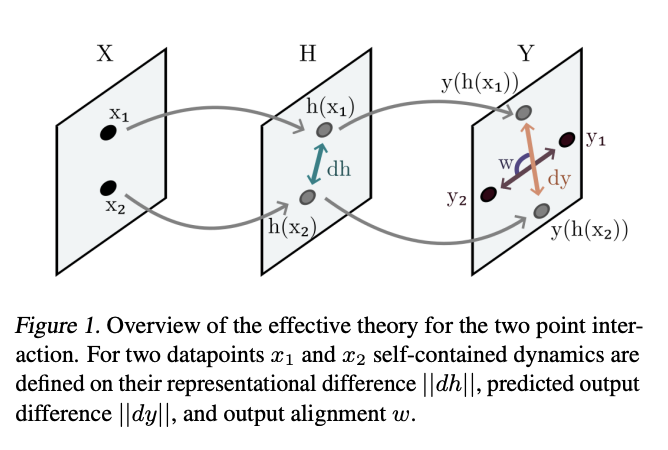
Researchers from the University College London have proposed a method for modeling universal representation learning, whose aim is to explain common phenomena observed in learning systems. An effective theory is developed for two similar data points to interact with each other during training when the neural network is large and complex, so, it’s not heavily limited by its parameters. Moreover, the existence of universal behavior is demonstrated in representational learning dynamics, by the fact that the derived theory explains the dynamics of various deep networks with different activation functions and architectures.
The proposed theory looks at the representation dynamics at “some intermediate layer H.” Since DNNs have many layers where representations can be observed, it poses a question of how these dynamics depend on the depth of the chosen intermediate layer. To answer this, it is necessary to determine on which layers the effective theory is still valid. For the linear approximation to be accurate, the representations must start close to each other. If the initial weights are small, each layer’s average activational gain factor is a constant G, which is less than 1. The initial representational distance is shown as a function of the depth n scales:
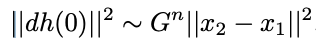
This function decreases, so the theory should be more accurate in the later layers of the network.
The effective learning rates are expected to vary at different hidden layers. In standard gradient descent, the update involves adding up the parameters, so changes are proportional to the number of parameters. In the deeper hidden layers, the number of parameters in the encoder map increases, while the number in the decoder map decreases. This causes the effective learning rate for the encoder to increase with depth and for the decoder to decrease with depth. This relationship holds for the deeper layers of the network where theory is accurate, however, in the earlier layers, the effective learning rate for the decoder appears to increase.
In summary, researchers from the University College London have introduced a new theory about how neural networks learn, focusing on their common learning patterns across different architectures. It shows that these networks naturally learn structured representations, especially when they start with small weights. Rather than presenting this theory as a definitive universal model, researchers highlighted that gradient descent, the fundamental method used in training neural networks, may support the aspects of representation learning. However, this approach faces challenges when applied to larger datasets, and further research is necessary to address these complexities effectively and deal with more complex data.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Researchers at the University College London Unravel the Universal Dynamics of Representation Learning in Deep Neural Networks appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]