


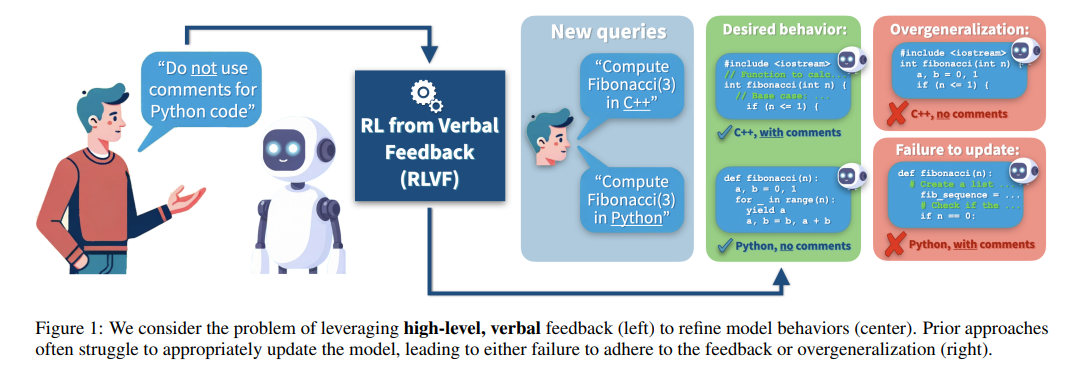
In the evolving landscape of artificial intelligence, language models transform interaction and information processing. However, aligning these models with specific user feedback while avoiding unintended overgeneralization poses a challenge. Traditional approaches often need to discern the applicability of feedback, leading to models extending rules beyond intended contexts. This issue highlights the need for advanced methods to ensure language models can adapt precisely to user preferences without compromising their utility in diverse applications.
Existing works have explored improving language or dialogue systems through various types of feedback, including learned or heuristic rewards, preferences or rankings, and natural language feedback. Natural language feedback has enhanced performance in code generation, dialogue, and summarization tasks. Some studies have focused on leveraging natural language feedback to refine general model behaviors rather than improving a single model output. Related research areas include constitutional AI, context distillation, model editing, and debiasing LLMs.
Researchers from Cornell University have introduced a novel method, Contextualized Critiques with Constrained Preference Optimization (C3PO), to refine models’ response behavior. The C3PO method strategically fine-tunes language models to apply feedback where relevant while averting overgeneralization meticulously. It achieves this by utilizing Direct Preference Optimization (DPO) for data deemed in-scope and Supervised Fine-Tuning (SFT) losses for out-of-scope and near-scope data, ensuring the model’s performance remains robust across various contexts.
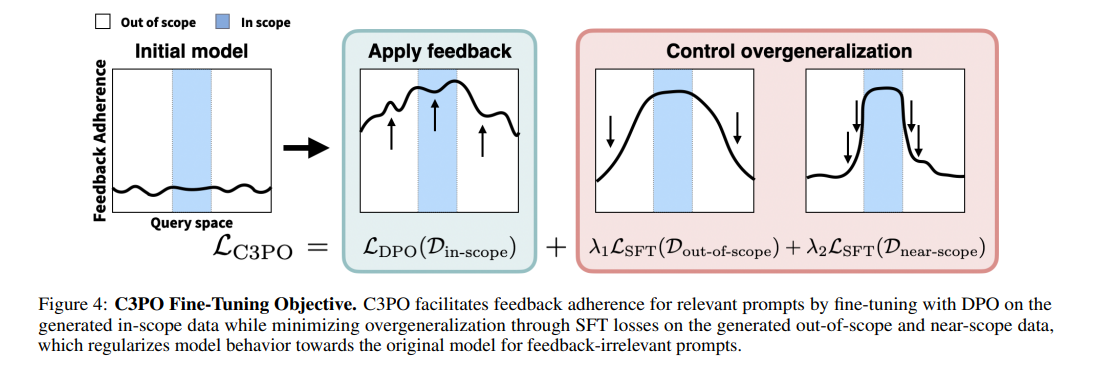
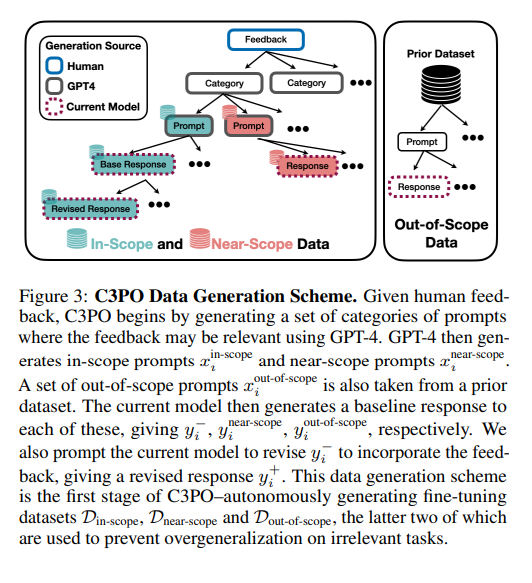
The generation of datasets Dnear-scope and Dout-of-scope, filled with prompts and completions from the initial model, maintains the model’s integrity for inputs unrelated to the feedback. Incorporating a sophisticated combined loss function, LC3PO, the approach not only embraces feedback for pertinent prompts but also actively prevents the model’s performance from deteriorating on irrelevant prompts. This is further enhanced by C3PO’s creation of synthetic two-policy preference data, which enables learning of the optimal policy under the Bradley-Terry preference model framework. This optimal policy delicately balances the model’s original capabilities with the new feedback, penalizing responses that deviate from the input, thus refining the model’s responses precisely, feedback-aligned.
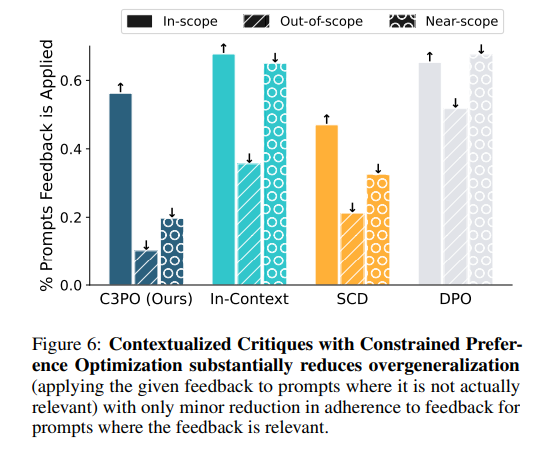
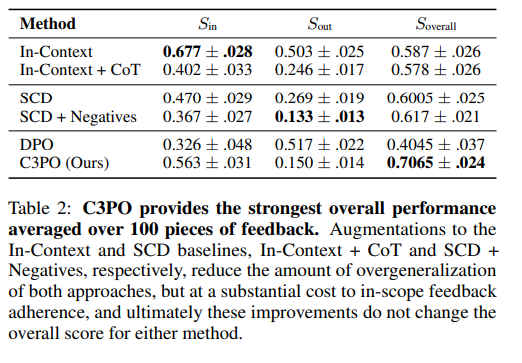
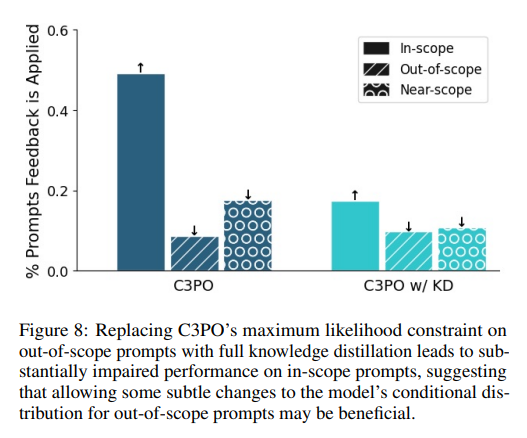
The experiments rigorously evaluate C3PO’s ability to incorporate verbal feedback without overgeneralizing, comparing it against traditional methods and exploring its proficiency in assimilating multiple feedbacks. Utilizing a feedback dataset of 100 entries, both authored and GPT-4 generated, C3PO demonstrates superior performance by effectively adhering to in-scope prompts while minimizing overgeneralization, a notable improvement over modified In-Context and SCD methods. Mixing Learned Low-Rank Adjustment (LoRA) parameters underscores C3PO’s efficient feedback integration, supported by a strategic constraint formulation that outperforms full knowledge distillation.
In conclusion, the development of C3PO marks a significant stride towards more adaptable and user-centric language models. By addressing the challenge of overgeneralization, this method paves the way for more personalized and efficient AI tools tailored to meet the diverse needs of users without sacrificing broader applicability. The implications of this research extend beyond technical achievements, heralding a future where AI can seamlessly adapt to individual preferences, enhancing both its utility and accessibility.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Researchers at Stanford Unveil C3PO: A Novel Machine Learning Approach for Context-Sensitive Customization of Large Language Models appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]