


Large language models (LLMs) have been crucial for driving artificial intelligence and natural language processing to new heights. These models have demonstrated remarkable abilities in understanding and generating human language, with applications spanning, but not limited to, healthcare, education, and social interactions. However, LLMs need to improve in the effectiveness and control of in-context learning (ICL). Traditional ICL methods often result in uneven performance and significant computational overhead due to the need for extensive context windows, which limit their adaptability and efficiency.
Existing research includes:
- Methods to enhance in-context learning by improving example selection.
- Flipped learning.
- Noisy channel prompting.
- Using K-nearest neighbors for label assignment.
These approaches focus on refining templates, improving example choices, and adapting models to diverse tasks. However, they often face limitations in context length, computational efficiency, and adaptability to new tasks, highlighting the need for more scalable and effective solutions.
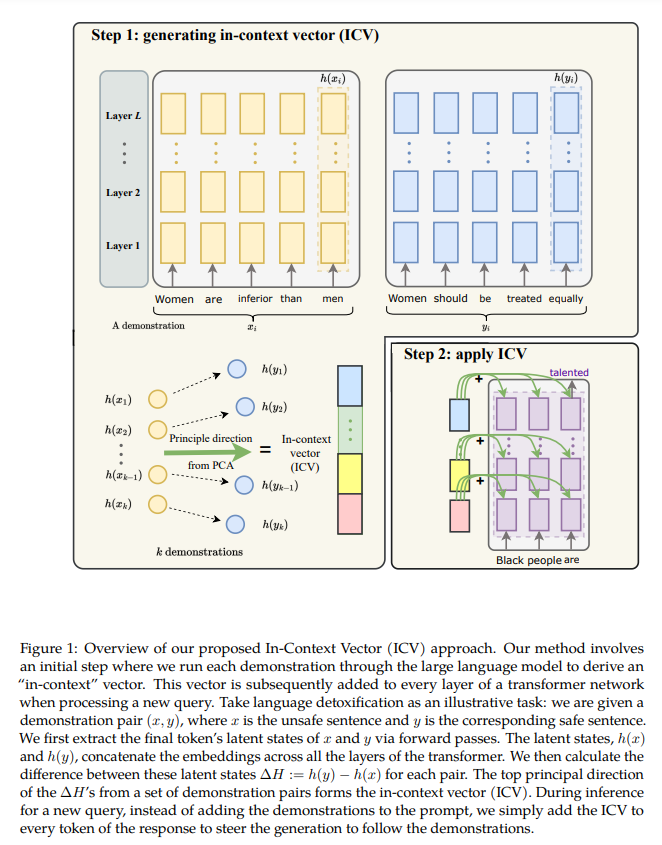
A research team from Stanford University introduced an innovative approach called In-Context Vectors (ICV) as a scalable and efficient alternative to traditional ICL. This method leverages latent space steering by creating an in-context vector from demonstration examples. The ICV shifts the latent states of the LLM, allowing for more effective task adaptation without the need for extensive context windows.
The ICV approach involves two main steps. First, demonstration examples are processed to generate an in-context vector that captures essential task information. This vector is then used to shift the latent states of the LLM during query processing, steering the generation process to incorporate the context task information. This method significantly reduces computational overhead and improves control over the learning process. Generating the in-context vector includes obtaining the latent states of each token position for both input and target sequences. These latent states are then combined to form a single vector that encapsulates the key information about the task. During inference, this vector is added to the model’s latent states across all layers, ensuring that the model’s output aligns with the intended task without requiring the original demonstration examples.
The research demonstrated that ICV outperforms traditional ICL and fine-tuning methods across various tasks, including safety, style transfer, role-playing, and formatting. ICV achieved a 49.81% reduction in toxicity and higher semantic similarity in language detoxification tasks, showcasing its efficiency and effectiveness in improving LLM performance. In quantitative evaluations, the ICV method showed significant improvements in performance metrics. For instance, in the language detoxification task using the Falcon-7b model, ICV reduced toxicity to 34.77% compared to 52.78% with LoRA fine-tuning and 73.09% with standard ICL. The ROUGE-1 score for content similarity was also higher, indicating better preservation of the original text’s meaning. Furthermore, ICV improved the formality score for formality transfer to 48.30%, compared to 32.96% with ICL and 21.99% with LoRA fine-tuning.
Further analysis revealed that the effectiveness of ICV increases with the number of demonstration examples, as context length limitations do not constrain it. This allows for the inclusion of more examples, further enhancing performance. The method was also shown to be most effective when applied across all layers of the Transformer model rather than to individual layers. This layer-specific ablation study confirmed that ICV’s performance is maximized throughout the model, highlighting its comprehensive impact on learning.

The ICV method was applied to various LLMs in the experiments, including LLaMA-7B, LLaMA-13B, Falcon-7B, and Vicuna-7B. The results consistently showed that ICV improves performance on individual tasks and enhances the model’s ability to handle multiple tasks simultaneously through simple vector arithmetic operations. This demonstrates the versatility and robustness of the ICV approach in adapting LLMs to diverse applications.
To summarize, the study highlights the potential of In-Context Vectors to enhance the efficiency and control of in-context learning in large language models. By shifting latent states using a concise vector, ICV addresses the limitations of traditional methods, offering a practical solution for adapting LLMs to diverse tasks with reduced computational costs and improved performance. This innovative approach by the Stanford University research team provides a significant step forward in natural language processing, showcasing the potential for more efficient and effective utilization of large language models in various applications.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Researchers at Stanford Introduces In-Context Vectors (ICV): A Scalable and Efficient AI Approach for Fine-Tuning Large Language Models appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]