


Natural language processing (NLP) has rapidly evolved with the development of large language models (LLMs), which are increasingly central to various tech applications. These models process and generate text in ways that mimic human understanding, but inefficiencies often hamper their potential in resource use and limitations imposed by proprietary data.
The overarching problem in LLMs is their resource intensity and restricted access due to reliance on private datasets. This increases the computational cost and limits the scope for academic research and development in open communities. In response to these challenges, many existing solutions adopt a uniform architectural approach, where each layer of the transformer model is configured identically. While this simplicity aids in model design, it does not optimize the use of parameters, potentially leading to wasteful computation and suboptimal performance.
OpenELM is a groundbreaking language model introduced by Apple researchers. This model revolutionizes the standard design by implementing a layer-wise scaling strategy, which allocates parameters more judiciously across the transformer layers. This approach allows for the adjustment of layer dimensions throughout the model, optimizing performance and computational efficiency.
OpenELM is distinct not just for its architectural innovations but also for its commitment to open-source development. The model is pre-trained on diverse public datasets, including RefinedWeb and PILE, totaling around 1.8 trillion tokens. This model has been shown to improve accuracy significantly; for instance, with just 1.1 billion parameters, OpenELM achieves a 45.93% accuracy rate, surpassing the OLMo model’s 43.57% while utilizing half the pre-training tokens.
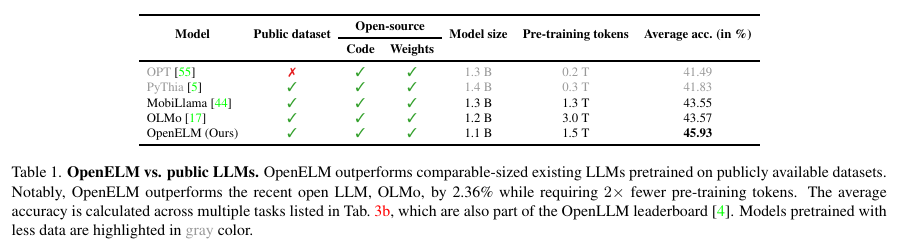
OpenELM’s performance excels across various standard metrics and tasks. For example, in zero-shot tasks like ARC-e and BoolQ, OpenELM surpasses existing models with fewer data and less computational expense. In direct comparisons, OpenELM demonstrates a 2.36% higher accuracy than OLMo with considerably fewer tokens. This efficiency is achieved through strategic parameter allocation, which maximizes the impact of each computational step.
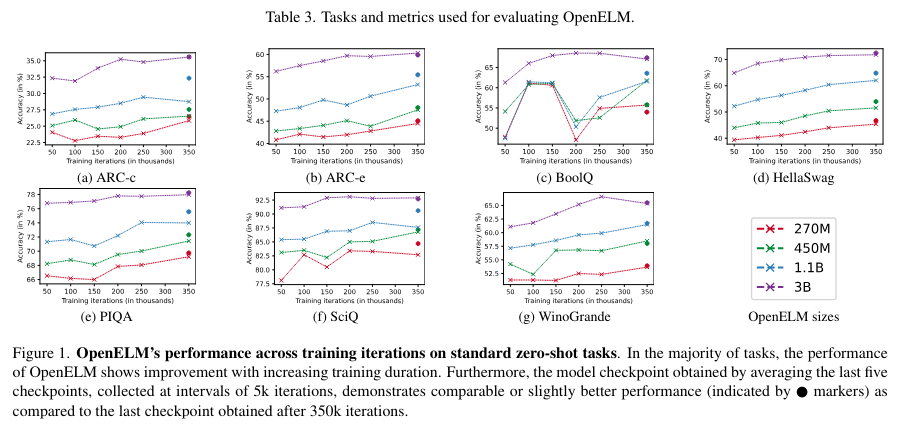
OpenELM marks a step forward in model efficiency and the democratization of NLP technology. By publicly releasing the model and its training framework, Apple fosters an inclusive environment that encourages ongoing research and collaboration. This approach will likely propel further NLP innovations, making high-performing language models more accessible and sustainable.

In conclusion, OpenELM addresses the inefficiencies of traditional large language models through its innovative layer-wise scaling technique, optimizing parameter distribution effectively. By utilizing publicly available datasets for training, OpenELM enhances computational efficiency and fosters open-source collaboration in the natural language processing community. The model’s impressive results, including a 2.36% higher accuracy over comparable models like OLMo while using half the pre-training tokens, highlight its potential to set new benchmarks for performance and accessibility in language model development.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post Researchers at Apple Release OpenELM: Model Improving NLP Efficiency Using Layer-Wise Innovation and Open-Source Approach appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]