


In artificial intelligence, scaling laws serve as useful guides for developing Large Language Models (LLMs). Like skilled directors, these laws coordinate models’ growth, revealing development patterns that go beyond mere computation. With each step forward, these models become more sophisticated, unlocking the intricacies of human expression with careful accuracy. Besides, scaling laws provide limitless potential for language, poised at the edge of comprehension and creation. It is usually studied in the compute-optimal training regime and predicts loss on next-token prediction.
However, there are gaps between current scaling studies and how language models are ultimately trained and evaluated. Training LLMs are expensive, and often over-trained to reduce inference costs and compare them based on downstream task performance. Training high-quality models requires a complex recipe of algorithmic techniques and training data. Researchers often use reliable extrapolation for the final training run, making it commonplace for training state-of-the-art language models such as Chinchilla 70B, PaLM 540B, and GPT-4.
Researchers from different universities experimented by creating a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three different data datasets: RedPajama, C4, and Refined Web to determine when scaling is predictable in the over-trained regime. This has helped predict the validation loss of a 1.4B parameter, 900B token run, and a 6.9B parameter, 138B token run. It relates the perplexity of a language model to its downstream task performance via a power law, which is used to predict top-1 error averages over downstream tasks for the two models above that take less computing time.
It has been observed that scaling laws when applied to smaller models trained closer to the compute-optimal, can effectively forecast the performance of larger models subject to more extensive over-training. However, predicting errors on individual tasks proves challenging. Hence, aggregate performance is reliably forecasted based on a model’s perplexity relative to models trained on the same dataset. During the research, it was found that, for a set of model configurations with a constant ratio of training tokens to parameters, the models’ reducible loss L′ follows consistent power laws (L′=λ·C−αc) in the amount of training computed C. So, if the ratio of tokens to parameters increases, the scaling exponent αC remains the same while the scalar λ changes.
To gauge the extent of over-training, token multipliers are used for well-known models. For instance, Chinchilla 70B is trained with a token multiplier of 20, while LLaMA-2 7B uses a token multiplier 290. Token multipliers from 5 to 640 are considered to ensure coverage of popular models and relevance for future models that may be trained on even more tokens. Analysis of data points trained on three datasets shows that exponential decay of average top-1 error as C4 eval loss on the x-axis decreases, as shown in the figure:
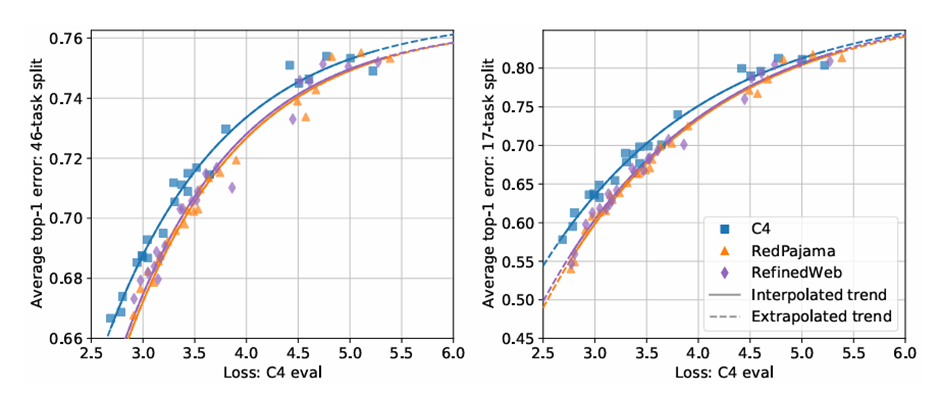
For the average error over 46 evaluations and the average error on a subset of 17 assessments, performance can be 10 points above random chance for at least one 0.154B scale model. These observations suggest that average top-1 error should be predictable with reliable loss estimates.
In conclusion, this research efficiently handles both the topics: scaling in the over-trained regime and downstream performance prediction. It shows that the loss scaling behavior of models trained past compute-optimal in the overtrained regime is predictable. Also, using the proposed scaling law, one can predict the downstream average task performance of more expensive runs using smaller-scale proxies. However, future development in scaling laws could focus on incorporating hyperparameters and developing an analytical theory to explain instances where scaling fails.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
The post Redefining Efficiency: Beyond Compute-Optimal Training to Predict Language Model Performance on Downstream Tasks appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]