


The relentless pursuit of refining artificial intelligence has led to the creation of sophisticated Large Language Models (LLMs) such as GPT-3 and GPT-4, significantly expanding the boundaries of machine understanding and interaction with human language. These models, developed by leading research institutions and tech giants, have showcased their potential by excelling in various reasoning tasks, from solving complex mathematical problems to understanding nuances in natural language.
Despite their success, these advanced models have their flaws. They sometimes need to improve, making logical errors that can detract from their overall effectiveness. Attempts to mitigate these inaccuracies have involved human intervention or the aggregation of multiple reasoning paths to refine the outputs. Yet, these methods often need help with scalability, continuous human oversight, and response consistency, which can limit their practical application.
A new method known as RankPrompt has been introduced by researchers from Northeastern University, Alibaba Group, and NiuTrans Research. It represents a significant departure from traditional approaches, enabling LLMs to evaluate and rank their reasoning outputs autonomously. RankPrompt leverages the models’ inherent capabilities to generate comparative examples by simplifying the process into comparative evaluations among different responses. It indicates a strategic pivot toward enhancing the accuracy of LLMs’ reasoning without requiring additional external resources.
RankPrompt’s approach involves guiding the models through a comparative evaluation of reasoning paths, enabling them to identify the most logical outcome independently. This process is enriched by the generation of comparison exemplars selected based on their ability to lead to correct conclusions. These exemplars act as benchmarks that assist models in systematically sifting through various reasoning options, thus sharpening their decision-making process.
Empirical evidence from the research demonstrates RankPrompt’s substantial impact on improving reasoning accuracy across a diverse array of tasks. Specifically, the method has been shown to increase the performance of models like ChatGPT and GPT-4 by up to 13% across 11 arithmetic and commonsense reasoning tasks. RankPrompt has aligned with human judgment 74% of the time in evaluating open-ended tasks on the AlpacaEval dataset, highlighting its robustness and effectiveness.
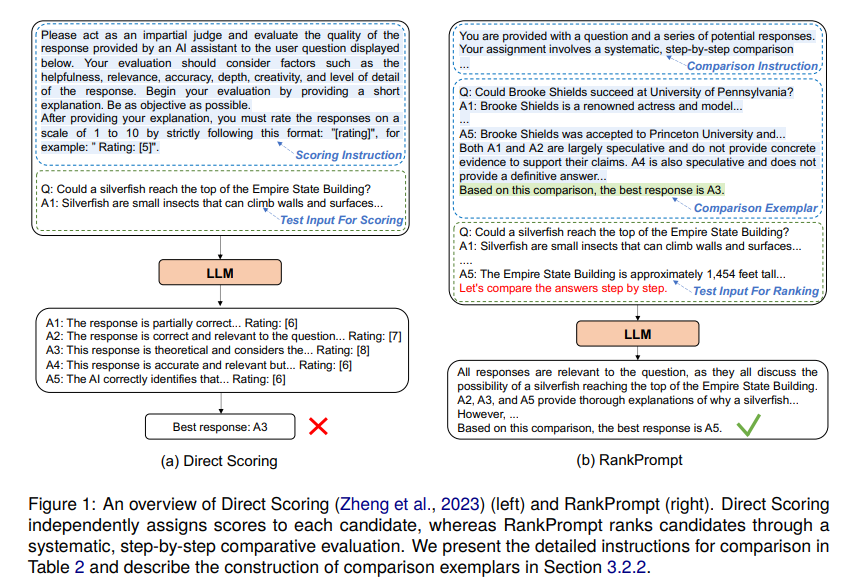
RankPrompt’s real-world applicability is underscored by its cost-effective and scalable solution to enhancing AI reasoning capabilities. By reducing the need for extensive manual intervention and harnessing the models’ inherent abilities, RankPrompt offers a forward-thinking solution to one of AI’s most persistent challenges.
In conclusion, the study of these findings presents RankPrompt as an innovative method in the AI field and a pivotal advancement in addressing the limitations of current language models. By equipping LLMs with the tools to refine their reasoning autonomously through comparative evaluation, RankPrompt opens new pathways for developing more reliable and efficient AI systems. This method’s success demonstrates the untapped potential of comparative assessment in unlocking the full reasoning capabilities of language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post RankPrompt: Revolutionizing AI Reasoning with Autonomous Evaluation with Improvement in Large Language Model Accuracy and Efficiency appeared first on MarkTechPost.
#AIPaperSummary #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]