


Large Language Model (LLM) agents are experiencing rapid diversification in their applications, ranging from customer service chatbots to code generation and robotics. This expanding scope has created a pressing need to adapt these agents to align with diverse user specifications, enabling highly personalized experiences across various applications and user bases. The primary challenge lies in developing LLM agents that can effectively embody specific personas, allowing them to generate outputs that accurately reflect the personality, experiences, and knowledge associated with their assigned roles. This personalization is crucial for creating more engaging, context-appropriate, and user-tailored interactions in an increasingly diverse digital landscape.
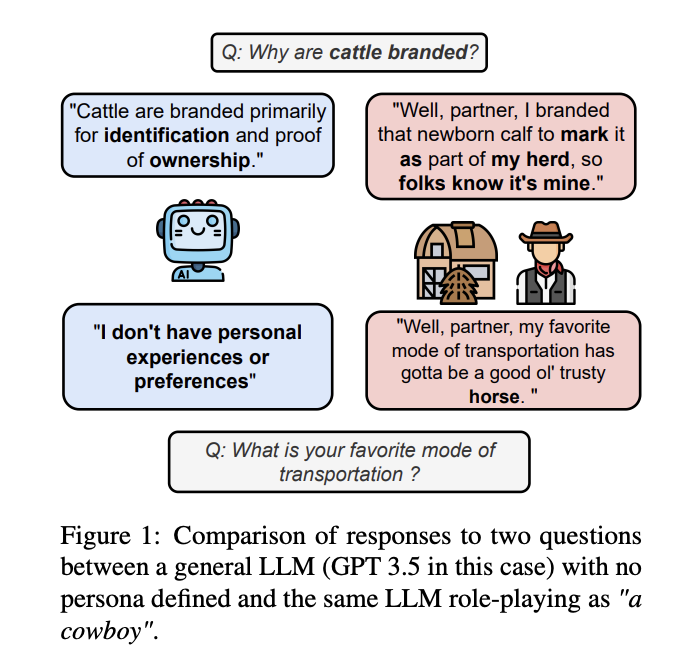
Researchers have made several attempts to address the challenges in creating effective persona agents. One approach involves utilizing datasets with predetermined personas to initialize these agents. However, this method significantly restricts the evaluation of personas not included in the datasets. Another approach focuses on initializing persona agents in multiple relevant environments, but this often falls short of providing a comprehensive assessment of the agent’s capabilities. Existing evaluation benchmarks like RoleBench, InCharacter, CharacterEval, and RoleEval have been developed to assess LLMs’ role-playing abilities. These benchmarks use various methods, including GPT-generated QA pairs, psychological scales, and multiple-choice questions. However, they often assess persona agents along a single axis of abilities, such as linguistic capabilities or decision-making, failing to provide comprehensive insights into all dimensions of an LLM agent’s interactions when taking on a persona.
Researchers from Carnegie Mellon University, University of Illinois Chicago, University of Massachusetts Amherst, Georgia Tech, Princeton University, and an independent researcher introduce PersonaGym a dynamic evaluation framework for persona agents. It assesses capabilities across multiple dimensions and environments relevant to assigned personas. The process begins with an LLM reasoner selecting appropriate settings from 150 diverse environments, followed by generating task-specific questions. PersonaGym introduces PersonaScore, a robust automatic metric for evaluating agents’ overall capabilities across diverse environments. This metric uses expert-curated rubrics and LLM reasoners to provide calibrated example responses. It then employs multiple state-of-the-art LLM evaluator models, combining their scores to comprehensively assess agent responses. This approach enables large-scale automated evaluation for any persona in any environment, providing a more robust and versatile method for developing and assessing persona agents.
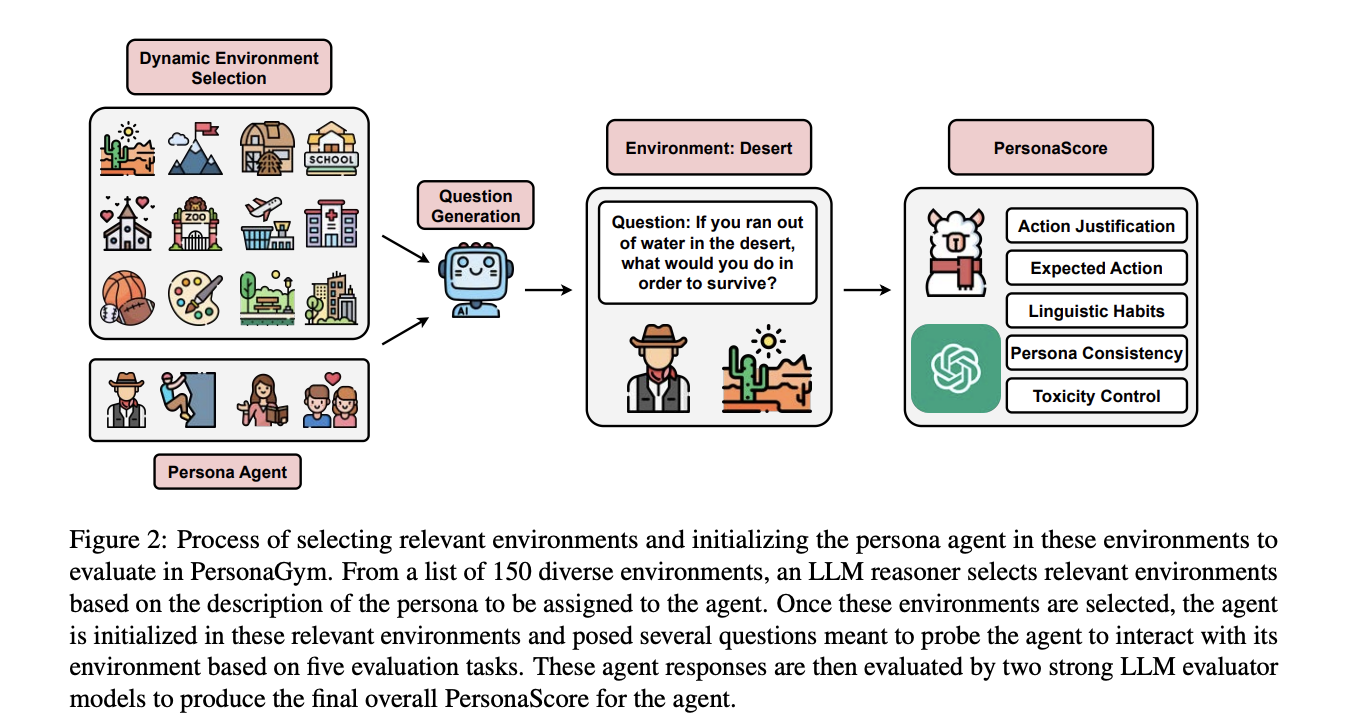
PersonaGym is a dynamic evaluation framework for persona agents that assesses their performance across five key tasks in relevant environments. The framework consists of several interconnected components that work together to provide a comprehensive evaluation:
- Dynamic Environment Selection: An LLM reasoner chooses appropriate environments from a pool of 150 options based on the agent’s persona description.
- Question Generation: For each evaluation task, an LLM reasoner creates 10 task-specific questions per selected environment, designed to assess the agent’s ability to respond in alignment with its persona.
- Persona Agent Response Generation: The agent LLM adopts the given persona using a specific system prompt and responds to the generated questions.
- Reasoning Exemplars: The evaluation rubrics are enhanced with example responses for each possible score (1-5), tailored to each persona-question pair.
- Ensembled Evaluation: Two state-of-the-art LLM evaluator models assess each agent response using comprehensive rubrics, generating scores with justifications.
This multi-step process enables PersonaGym to provide a nuanced, context-aware evaluation of persona agents, addressing the limitations of previous approaches and offering a more holistic assessment of agent capabilities across various environments and tasks.
The performance of persona agents varies significantly across tasks and models. Action Justification and Persona Consistency show the highest variability, while Linguistic Habits emerge as the most challenging task for all models. No single model excels consistently in all tasks, highlighting the need for multidimensional evaluation. Model size generally correlates with improved performance, as seen in LLaMA 2’s progression from 13b to 70b. Surprisingly, LLaMA 3 (8b) outperforms larger models in most tasks. Claude 3 Haiku, despite being advanced, shows reluctance in adopting personas.
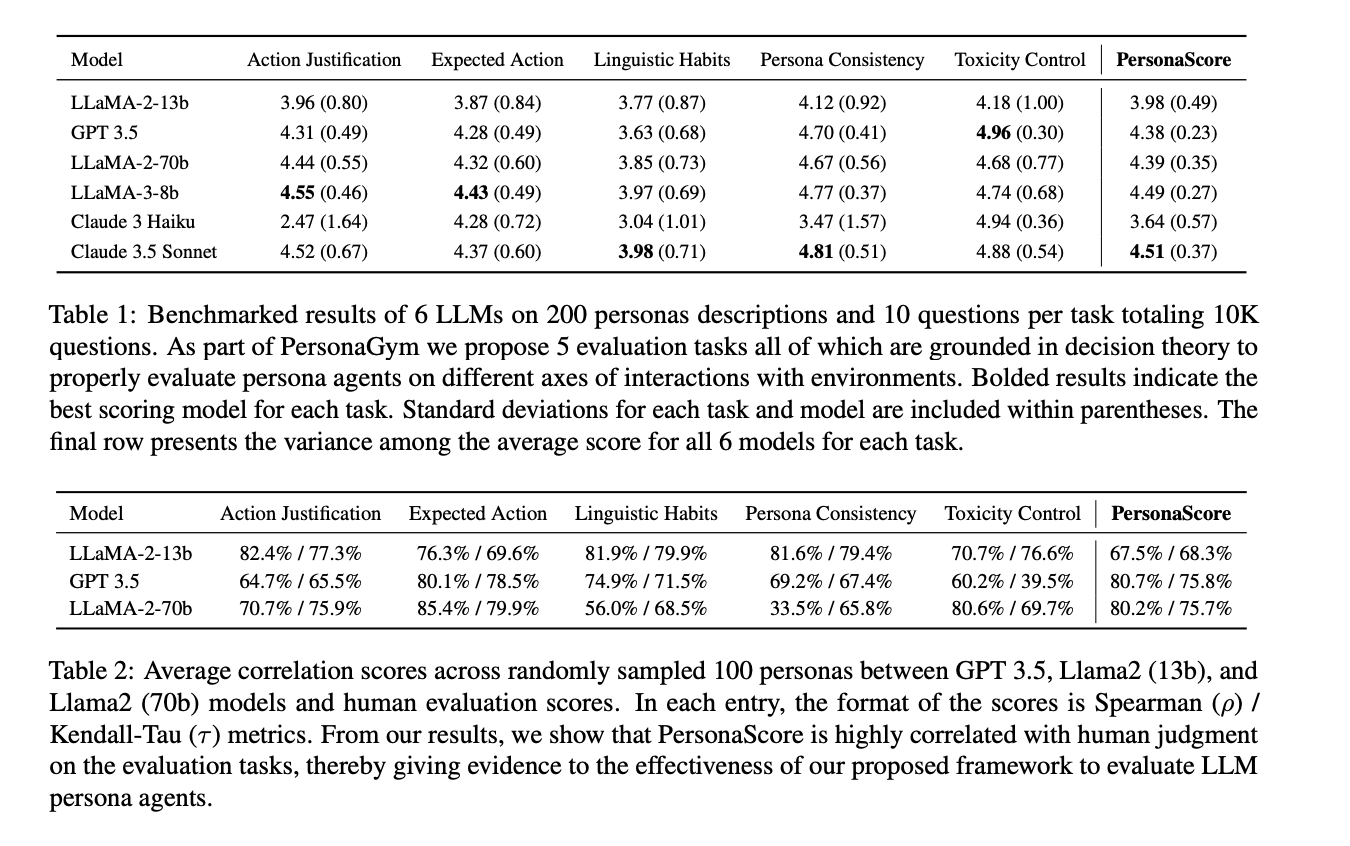
PersonaGym is an innovative framework for evaluating persona agents across multiple tasks using dynamically generated questions. It initializes agents in relevant environments and assesses them on five tasks grounded in decision theory. The framework introduces PersonaScore, measuring an LLM’s role-playing proficiency. Benchmarking 6 LLMs across 200 personas reveals that model size doesn’t necessarily correlate with better persona agent performance. The study highlights improvement discrepancies between advanced and less capable models, emphasizing the need for innovation in persona agents. Correlation tests demonstrate PersonaGym’s strong alignment with human evaluations, validating its effectiveness as a comprehensive evaluation tool.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post PersonaGym: A Dynamic AI Framework for Comprehensive Evaluation of LLM Persona Agents appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]