


Large language models (LLMs) possess advanced language understanding, enabling a shift in application development where AI agents communicate with LLMs via natural language prompts to complete tasks collaboratively. Applications like Microsoft Teams and Google Meet use LLMs to summarize meetings, while search engines like Google and Bing enhance their capabilities with chat features. These LLM-based applications often require multiple API calls, creating complex workflows. Current API designs for LLM services are request-centric and lack application-level information, which results in sub-optimal performance.
The field of model serving has seen significant advancements with systems like Clipper, TensorFlow Serving, and AlpaServe addressing deep learning deployment challenges. These systems focus on batching, caching, and scheduling but often overlook the unique needs of LLMs. Orca and vLLM improve batching and memory utilization for LLM requests. Parrot enhances LLM serving by analyzing application-level data flow, and optimizing end-to-end performance. LLM orchestrator frameworks like LangChain and Semantic Kernel simplify LLM application management. Parrot integrates with these frameworks, utilizing Semantic Variables for optimization. Parrot also uses DAG information to optimize LLM applications, emphasizing prompt structure and request dependencies.
Researchers from Shanghai Jiao Tong University and Microsoft Research proposed Parrot, an LLM service system designed to treat LLM applications as first-class citizens, retaining application-level information through the use of Semantic Variables. A Semantic Variable is a text region in a prompt with a specific semantic purpose, such as task instructions or inputs, and it connects multiple LLM requests. By exposing prompt structures and request correlations, Parrot enables data flow analysis, optimizing end-to-end performance. Parrot’s unified abstraction facilitates joint optimizations, improving scheduling, latency hiding, and de-duplication.
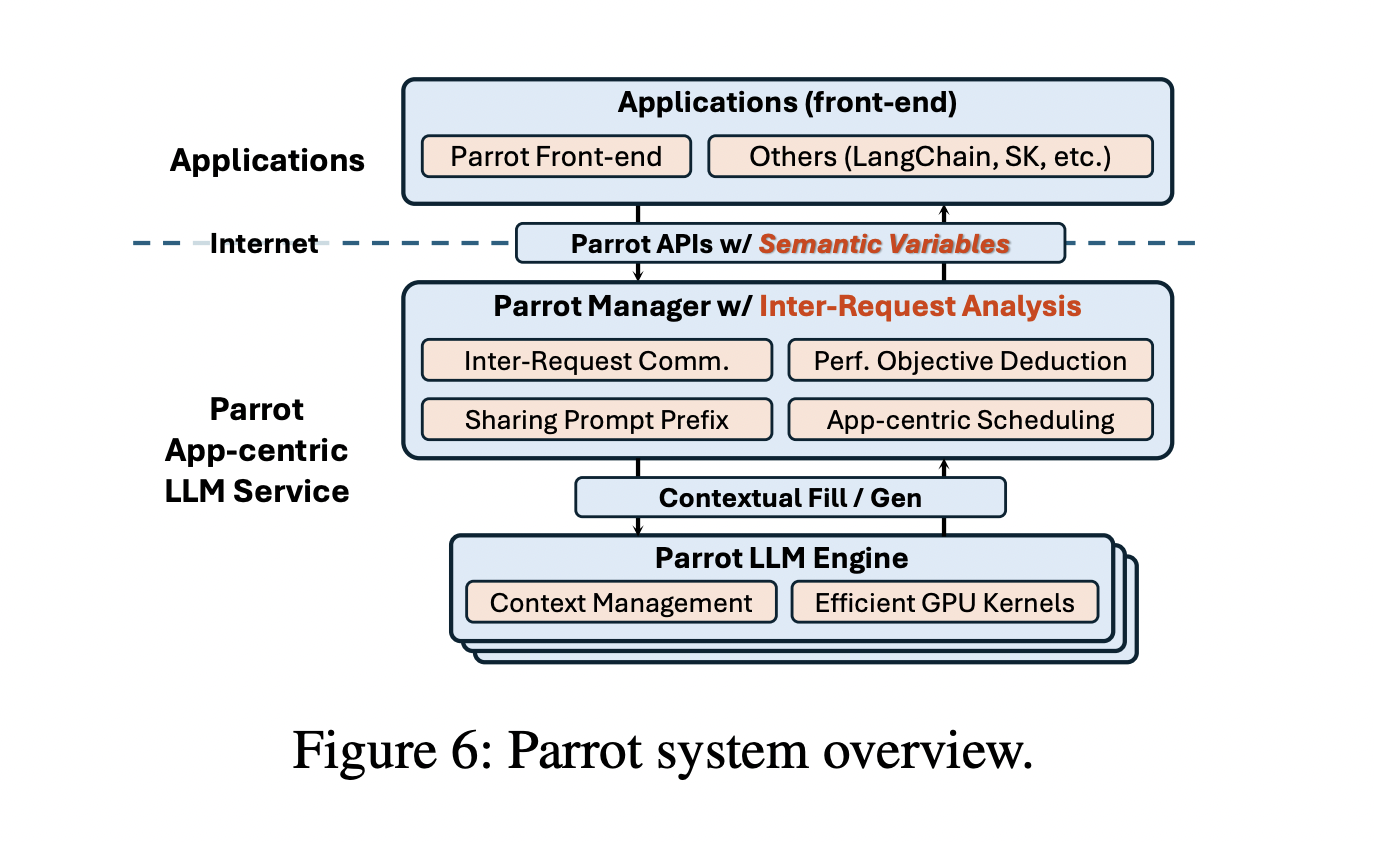
Parrot treats LLM requests as semantic functions implemented in natural language, executed by LLMs. Semantic Variables, defined as input or output placeholders in prompts, maintain the prompt structure for inter-request analysis. In multi-agent applications, such as MetaGPT, semantic functions like WritePythonCode and WriteTestCode use Semantic Variables to connect and sequence tasks. Parrot’s asynchronous design allows submitting and fetching requests separately, facilitating just-in-time relationship analysis. Performance criteria can be annotated for each variable, optimizing and scheduling based on end-to-end requirements like latency or throughput.
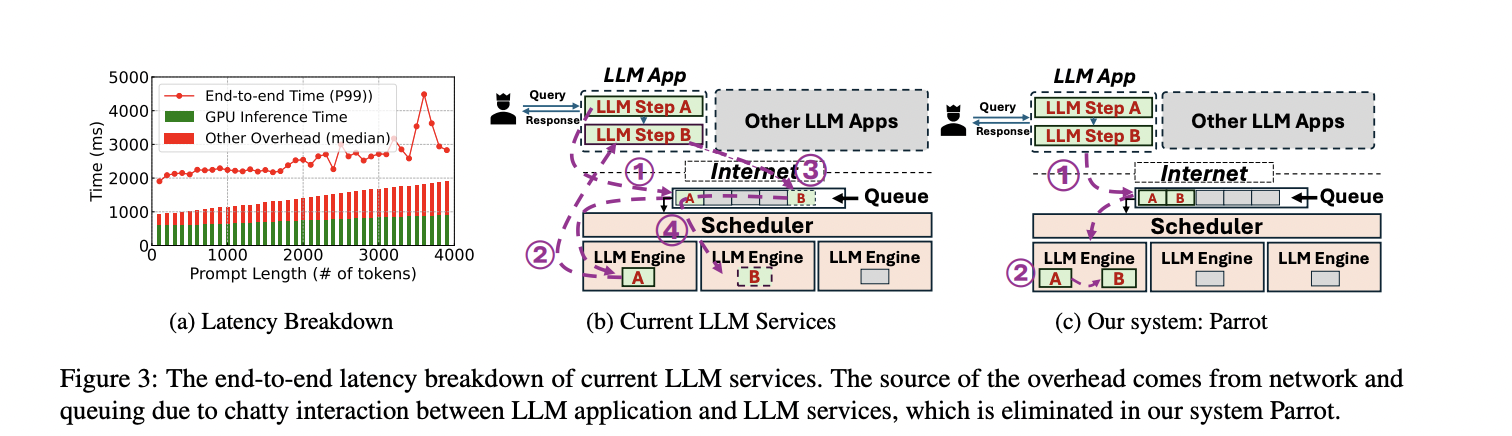
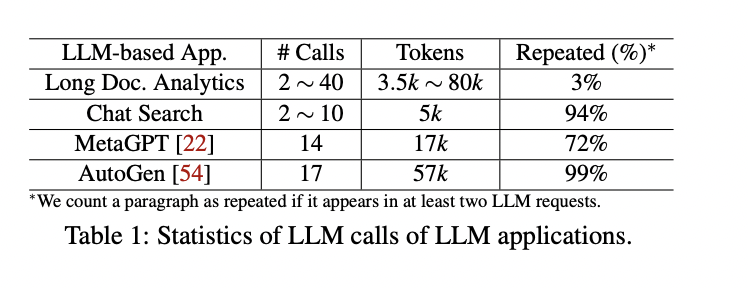
Evaluating Parrot on both production and open-source LLM-based applications reveals significant improvements, achieving up to 11.7× speedup and 12× higher throughput compared to state-of-the-art solutions. These applications require numerous LLM calls, leading to high user-perceived latency. Treating requests individually can double end-to-end latency, but Parrot’s batching approach eliminates this overhead. By scheduling consecutive requests together, Parrot directly feeds outputs from one step to the next, bypassing network and queuing delays.
This study introduces Parrot, which optimizes the end-to-end performance of LLM applications by treating them as first-class citizens rather than focusing solely on individual requests. It introduces Semantic Variable, an abstraction that reveals dependencies and commonalities among LLM requests, creating new optimization opportunities. The evaluation demonstrates Parrot can enhance LLM-based applications by up to 11.7×. This approach opens new research directions for improving scheduling features, such as ensuring the fairness of end-to-end performance in LLM applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post Parrot: Optimizing End-to-End Performance in LLM Applications Through Semantic Variables appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]