


The significance of computing and data size is undeniable in large-scale multimodal learning. Still, collecting data from high-quality video text is always challenging due to its temporal structure. Vision-language datasets (VLDs) like HD-VILA-100M and HowTo100M are extensively employed across various tasks, including action recognition, video understanding, VQA, and retrieval. These models are annotated by automatic speech recognition (ASR), enabling them to transcribe spoken language into text and enhance their performance.
However, meta-information like subtitles, video descriptions, and voice-overs frequently need more precision due to being overly broad, misaligned in timing, or insufficiently descriptive of the video content. If we are using VLDs like HD-VILA-100M and HowTo100M, the subtitles usually fail to include the main content and action presented in the video. This limitation reduces the effectiveness of these datasets for multimodal training. Some datasets suffer from low resolution, ASR annotations, small-scale samples, or brief captions.
Researchers from Snap Inc., the University of California, Merced, and the University of Trento proposed Panda-70M to tackle the challenge of generating high-quality video captions. Panda-70M leverages multimodal inputs, such as textual video description, subtitles, and individual video frames, to establish a video dataset with high-quality captions by curating 3.8M high-resolution videos from publicly available HD-VILA-100M datasets. Also, to use several captioning, Panda-70M incorporates five base models – Video LLaMA, VideoChat, VideoChat Text, BLIP-2, and MiniGPT-4 as teacher models. Researchers follow established protocols and evaluate metrics like BLEU-4, ROGUE-L, METEOR, and CIDEr.
To develop Panda-70M, meticulously crafted 3.8M high-resolution videos are split into semantically consistent video clips, leveraging multiple cross-modality teacher models. Then, a fine-grained retrieval model is fine-tuned to obtain captions for each video. The models trained on the proposed data score consistently outperform others on most metrics, demonstrating their superiority in various tasks. Compared to other VLDs, Panda-70M took 8.5 seconds on average to process a video of length 166.8Khr, which is the most efficient of all VLDs.
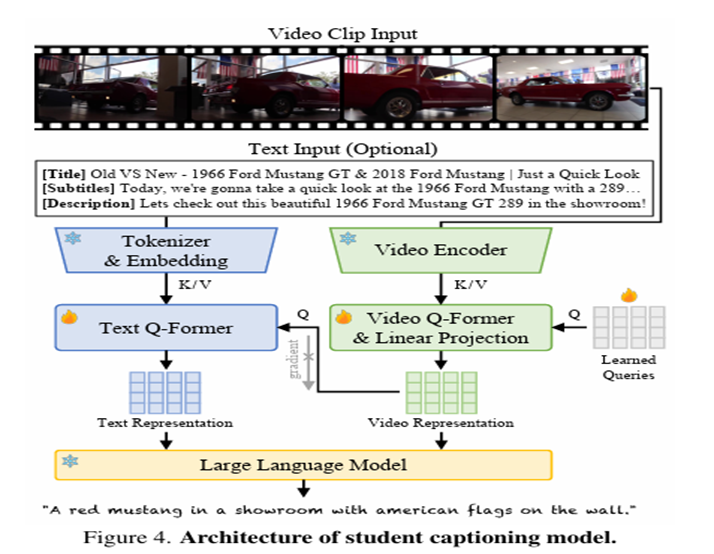
In visual processing, we utilize a familiar framework, similar to the one employed in Video LLaMA, to derive video representations compatible with LLM. For the text branch, a direct approach would be to input text embedding directly into the LLM. However, this poses two challenges:
- Lengthy text prompts containing video descriptions and subtitles may overwhelm the LLM’s decision-making process, resulting in computationally intensive burdens.
- The information derived from descriptions and subtitles can often be noisy and irrelevant to the video content.
- Researchers also introduced text Q-former, designed to extract fixed-length text representations, thereby fostering a more seamless connection between video and text representations. This Q-former mirrors the architecture of the Query Transformer found in BLIP-2.
In conclusion, this research introduces a large-scale video dataset with caption annotations called Panda-70M. An automatic pipeline that can leverage multimodal information has been proposed to caption 70M videos and facilitate three downstream tasks: video captioning, video and text retrieval, and text-to-video generation. Despite impressive results, Panda-70M limits the content diversity within a single video and reduces average video duration; thus, it fails to build datasets with long videos.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Panda-70M: A Large-Scale Dataset with 70M High-Quality Video-Caption Pairs appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]