


The rapid advancement of large language models (LLMs) has significantly impacted various domains, offering unprecedented capabilities in processing and generating human language. Despite their remarkable achievements, the substantial computational costs of training these gargantuan models have raised financial and environmental sustainability concerns. In this context, exploring Mixture of Experts (MoE) models emerges as a pivotal development to enhance training efficiency without compromising model performance.
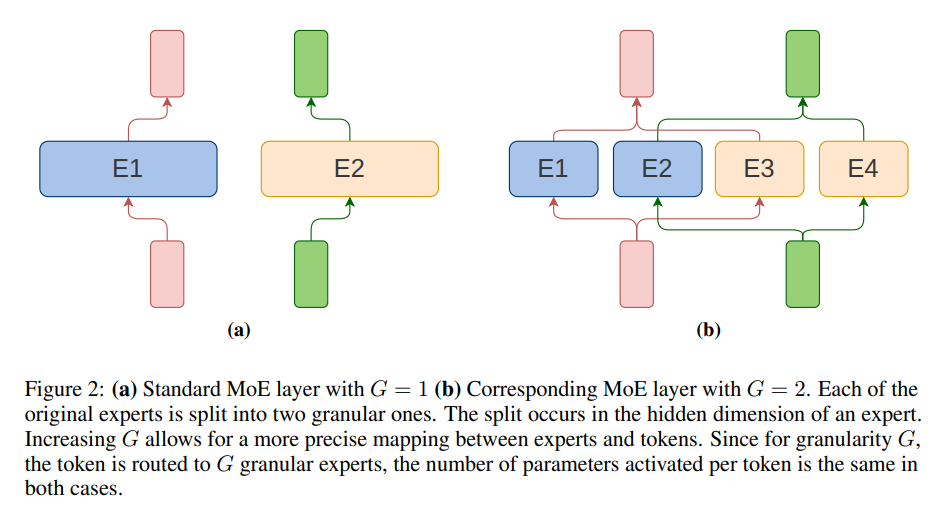
MoE models introduce a paradigm shift by employing a dynamic allocation of tasks to specialized subsets within the model, known as experts. This innovative approach optimizes computational resources by activating only relevant parts of the model for specific tasks. Researchers from the University of Warsaw, IDEAS NCBR, IPPT PAN, TradeLink, and Nomagic explored the scaling properties of MoE models. Their study introduces granularity as a critical hyperparameter, enabling precise control over the size of the experts and thereby refining the model’s computational efficiency.
The research delves into formulating new scaling laws for MoE models, considering a comprehensive range of variables, including model size, the number of training tokens, and granularity. This analytical framework provides insights into optimizing training configurations for maximum efficiency for a given computational budget. The study’s findings challenge conventional wisdom, particularly the practice of equating the size of MoE experts with the feed-forward layer size, revealing that such configurations are seldom optimal.
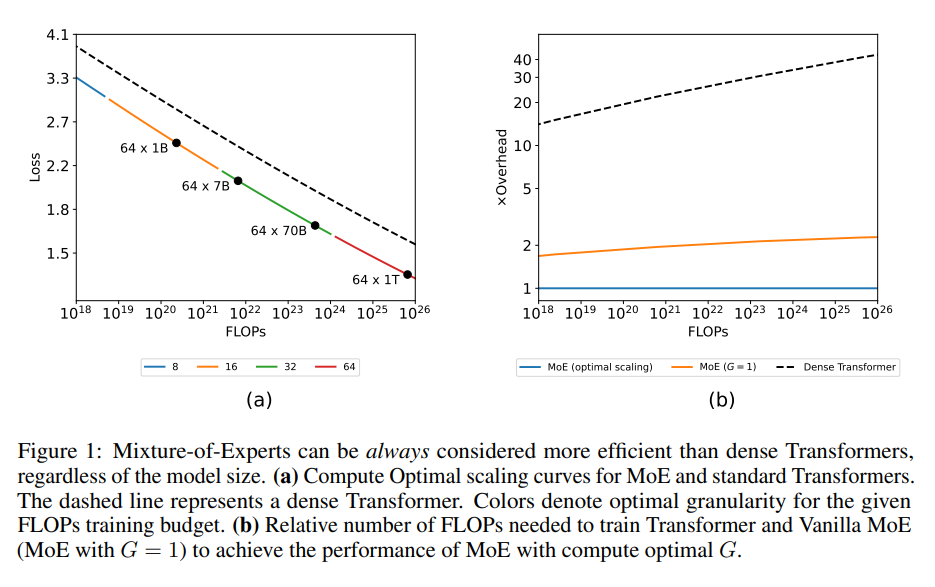
The researchers demonstrate that MoE models, when fine-tuned with appropriate granularity settings, consistently outshine dense transformer models across diverse computational budgets. This efficiency gap between MoE and thick models widens with the increase in model size and computational allocation, highlighting the significant potential of MoE models in the evolution of LLM training methodologies.
Important takeaways from this groundbreaking study include the following:
- By adjusting this novel hyperparameter, researchers can fine-tune the size of the experts within MoE models, significantly enhancing computational efficiency.
- The development of scaling laws incorporating granularity and other critical variables offers a strategic framework for optimizing MoE models. This approach ensures superior performance and efficiency compared to traditional dense transformer models.
- The study provides evidence that matching the size of MoE experts with the feed-forward layer size is not optimal, advocating for a more nuanced approach to configuring MoE models.
- The findings reveal that MoE models, when optimally configured, can outperform dense models in efficiency and scalability, particularly at larger model sizes and computational budgets. This efficiency advantage underscores MoE models’ transformative potential in reducing the financial and environmental costs associated with training LLMs.
In summary, this research marks a significant stride toward more efficient and sustainable training methodologies for large language models. By harnessing the capabilities of MoE models and the strategic adjustment of granularity, the study contributes to the theoretical understanding of model scaling. It provides practical guidelines for optimizing computational efficiency in LLM development. The implications of these findings are profound and promising, shaping the future landscape of artificial intelligence research and development.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post Optimizing Large Language Models with Granularity: Unveiling New Scaling Laws for Mixture of Experts appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]