


Instant Voice Cloning (IVC) in Text-to-Speech (TTS) synthesis, also known as Zero-shot TTS, allows TTS models to replicate the voice of any given speaker with just a short audio sample without requiring additional training on that speaker. While existing methods like VALLE and XTTS can replicate tone color, they need more flexibility in controlling style parameters like emotion, accent, and rhythm. Auto-regressive models, though effective, are computationally expensive and slow. Non-autoregressive approaches like YourTTS and Voicebox offer faster inference but lack comprehensive style control. Additionally, achieving cross-lingual voice cloning demands extensive datasets, hindering the inclusion of new languages. Closed-source projects further impede collaborative advancement in the field.
MIT CSAIL, MyShell.ai, and Tsinghua University researchers have developed OpenVoice V2, a groundbreaking text-to-speech model enabling voice cloning across languages. OpenVoice V2 transcends language barriers, offering applications like personalized digital interfaces, multilingual virtual assistants, and automatic dubbing. With enhanced audio quality and native support for English, Spanish, French, Chinese, Japanese, and Korean, OpenVoice V2 surpasses its predecessor. It allows granular control over voice styles, including emotion and accent, without relying on the reference speaker’s style. Moreover, it achieves zero-shot cross-lingual voice cloning, even for languages absent from its training data, while maintaining computational efficiency and real-time inference capabilities.
Prior research in IVC encompasses auto-regressive methods like VALLE and XTTS, extracting speaker characteristics to generate speech sequentially. While effectively replicating tone color, they lack flexibility in adjusting style parameters like emotion and accent. These models are computationally intensive and slow. Non-auto-regressive approaches like YourTTS and Voicebox offer faster inference but struggle with style parameter control. Additionally, they often rely on extensive datasets for cross-lingual cloning, limiting language inclusivity. Closed-source research from tech giants hampers collaborative progress in the field, hindering innovation and accessibility for the research community.
OpenVoice V2 integrates features from its predecessor and introduces Accurate Tone Color Cloning, Flexible Voice Style Control, and Zero-shot Cross-lingual Voice Cloning. The model’s simplicity lies in decoupling tone color cloning from style and language control, achieved through a base speaker TTS model and a tone color converter. The TTS model handles style and language, while the converter embodies the reference speaker’s tone color. Training involves collecting datasets for TTS and tone color conversion separately. The model structure employs flow layers for tone color conversion, ensuring natural sound while removing tone color information. The approach facilitates fluent multilingual speech generation.
The evaluation of voice cloning faces challenges in objectivity due to variations in training/test sets and objectives across studies. OpenVoice focuses on tone color cloning, style parameter control, and cross-lingual cloning. Rather than numerical comparisons, it emphasizes qualitative analysis, offering publicly available audio samples for assessment. It accurately clones tone color across diverse voice distributions, preserves various speech styles, and enables cross-lingual cloning with minimal speaker data. OpenVoice’s feed-forward structure ensures rapid inference, achieving 12× real-time performance on a single A10G GPU, with potential for further optimization.
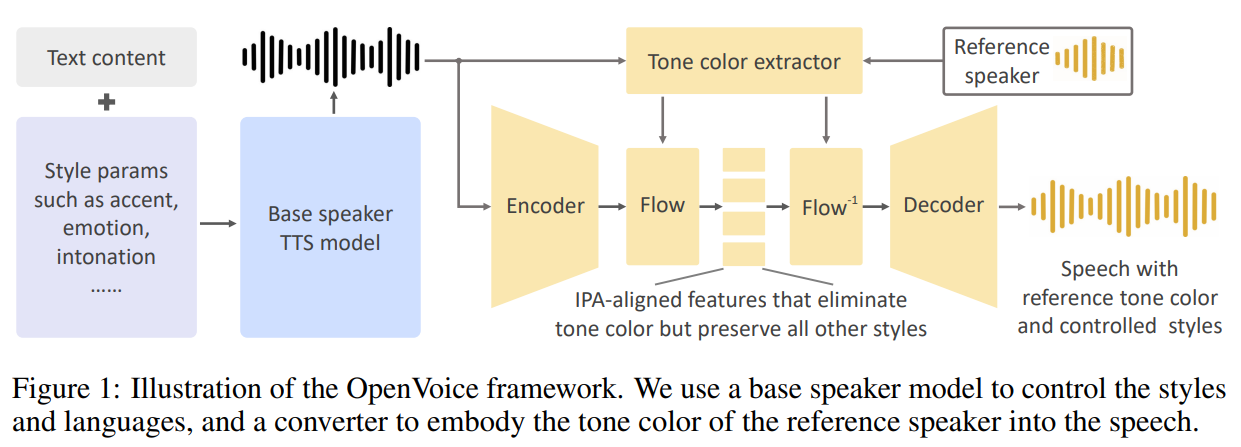
In conclusion, OpenVoice V2 enhances audio quality through a revised training strategy and introduces native English, Spanish, French, Chinese, Japanese, and Korean support. V1 and V2 are now available for free commercial use under the MIT License. Building upon V1’s features, V2 excels in tone color cloning across languages and accents, offers precise control over voice styles, and enables zero-shot cross-lingual cloning. By decoupling tone color cloning from other voice styles and languages, OpenVoice achieves greater flexibility and provides its source code and model weights for future research.
The post OpenVoice V2: Evolving Multilingual Voice Cloning with Enhanced Style Control and Cross-Lingual Capabilities appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]