


The release of the European LLM Leaderboard by the OpenGPT-X team presents a great milestone in developing and evaluating multilingual language models. The project, supported by TU Dresden and a consortium of ten partners from various sectors, aims to advance language models’ capabilities in handling multiple languages, thereby reducing digital language barriers and enhancing the versatility of AI applications across Europe.
The digital processing of natural language has seen advancements in recent years, largely due to the proliferation of open-source Large Language Models (LLMs). These models have demonstrated remarkable capabilities in understanding and generating human language, making them indispensable tools in various fields such as technology, education, and communication. However, most of these benchmarks have traditionally focused on the English language, leaving a gap in the support for multilinguality.
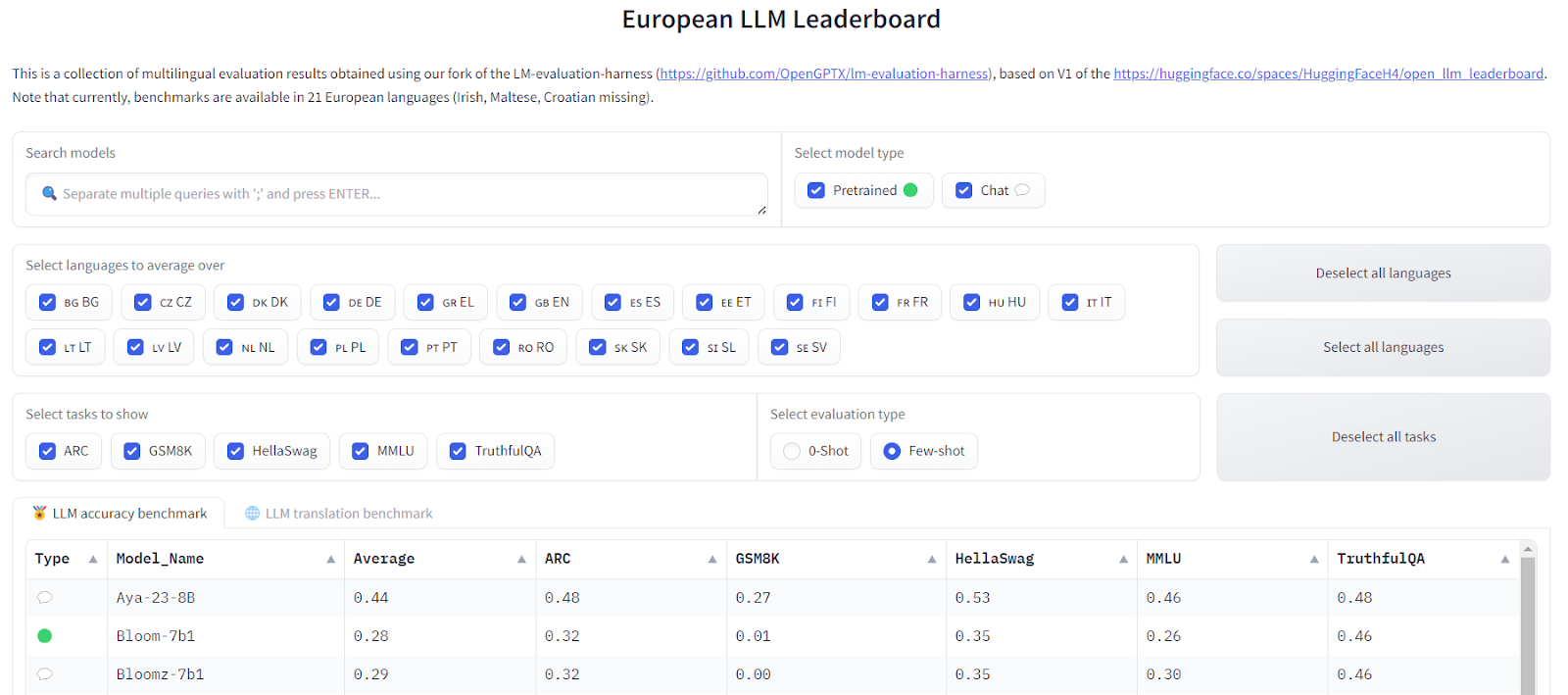
Recognizing this need, the OpenGPT-X project was launched in 2022 under the auspices of the BMWK. The project brings together business, science, and media experts to develop and evaluate multilingual LLMs. The recent publication of the European LLM Leaderboard is a pivotal step towards achieving the project’s goals. This leaderboard compares several state-of-the-art language models, each comprising approximately 7 billion parameters, across multiple European languages.
The primary aim of the OpenGPT-X consortium is to broaden language accessibility and ensure that AI’s benefits are not limited to English-speaking regions. To this end, the team conducted extensive multilingual training and evaluation, testing the developed models on various tasks, such as logical reasoning, commonsense understanding, multi-task learning, truthfulness, and translation.
Common benchmarks like ARC, HellaSwag, TruthfulQA, GSM8K, and MMLU were machine-translated into 21 of the 24 supported European languages using DeepL to enable comprehensive and comparable evaluations. Additionally, two further multilingual benchmarks already available for the project’s languages were included in the leaderboard. This approach ensures that the evaluation metrics are consistent and the results are comparable across different languages.
The evaluation of these multilingual models is automated through the AI platform Hugging Face Hub, with TU Dresden providing the necessary infrastructure to run the evaluation jobs on their HPC cluster. This infrastructure supports the scalability and efficiency required for handling large datasets and complex evaluation tasks. The release of the European LLM Leaderboard is just the beginning; the OpenGPT-X models will be published in the summer, making them accessible for further research and development.
TU Dresden’s involvement in the OpenGPT-X project is bolstered by its two competence centers: ScaDS.AI (Scalable Data Analytics and Artificial Intelligence) and ZIH (Information Services and High-Performance Computing). These centers consolidate expertise in training and evaluating large language models on supercomputing clusters. Their joint efforts focus on developing scalable evaluation pipelines, integrating various benchmarks, and performing comprehensive evaluations to improve model performance and scalability continuously.
Several benchmarks have been translated and employed in the project to assess the performance of multilingual LLMs:
- ARC and GSM8K: Focus on general education and mathematics.
- HellaSwag and TruthfulQA: Test the ability of models to provide plausible continuations and truthful answers.
- MMLU: Provides a wide range of tasks to assess the models’ capabilities across different domains.
- FLORES-200: Aimed at assessing machine translation skills.
- Belebele: Focuses on understanding and answering questions in multiple languages.
In conclusion, the European LLM Leaderboard by the OpenGPT-X team addresses the need for broader language accessibility and provides robust evaluation metrics. The project paves the way for more inclusive and versatile AI applications. This progress is particularly crucial for languages traditionally underrepresented in natural language processing.
Check out the Leaderboard and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post OpenGPT-X Team Publishes European LLM Leaderboard: Promoting the Way for Advanced Multilingual Language Model Development and Evaluation appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #Staff #TechNews #Technology #Leaderboard [Source: AI Techpark]