


Long-context understanding and retrieval-augmented generation (RAG) in large language models (LLMs) is rapidly advancing, driven by the need for models that can handle extensive text inputs and provide accurate, efficient responses. These capabilities are essential for processing large volumes of information that cannot fit into a single prompt, which is crucial for tasks such as document summarization, conversational question answering, and information retrieval.
The performance gap between open-access LLMs and proprietary models like GPT-4-Turbo remains a significant challenge. While open-access models like Llama-3-70B-Instruct and QWen2-72B-Instruct have enhanced their capabilities, they often need to catch up in processing large text volumes and retrieval tasks. This gap is particularly evident in real-world applications, where the ability to handle long-context inputs and retrieve relevant information efficiently is critical. Current methods for enhancing long-context understanding involve extending the context window of LLMs and employing RAG. These techniques complement each other, with long-context models excelling in summarizing large documents and RAG efficiently retrieving relevant information for specific queries. However, existing solutions often suffer from context fragmentation and low recall rates, undermining their effectiveness.
Researchers from Nividia introduced ChatQA 2, a Llama3-based model developed to address these challenges. ChatQA 2 aims to bridge the gap between open-access and proprietary LLMs in long-context and RAG capabilities. By extending the context window to 128K tokens and using a three-stage instruction tuning process, ChatQA 2 significantly enhances instruction-following, RAG performance, and long-context understanding. This model achieves a context window extension from 8K to 128K tokens through continuous pretraining on a mix of datasets, including the SlimPajama dataset with upsampled long sequences, resulting in 10 billion tokens with a sequence length of 128K.
The technology behind ChatQA 2 involves a detailed and reproducible technical recipe. The model’s development begins with extending the context window of Llama3-70B from 8K to 128K tokens by continually pretraining it on a mix of datasets. This process uses a learning rate of 3e-5 and a batch size 32, training for 2000 steps to process 8 billion tokens. Following this, a three-stage instruction tuning process is applied. The first two stages involve training on high-quality instruction-following datasets and conversational QA data with provided context. In contrast, the third stage focuses on long-context sequences up to 128K tokens. This comprehensive approach ensures that ChatQA 2 can handle various tasks effectively.
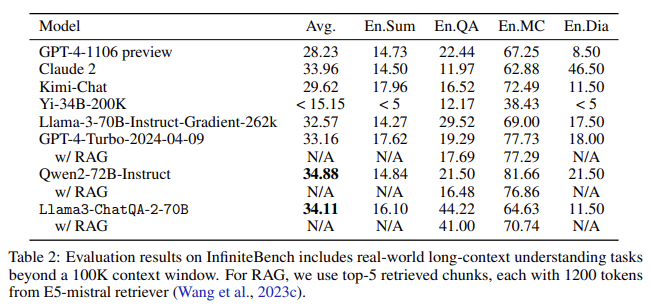
ChatQA 2 achieves accuracy comparable to GPT-4-Turbo-2024-0409 on many long-context understanding tasks and surpasses it in RAG benchmarks. For instance, in the InfiniteBench evaluation, which includes functions like longbook summarization, QA, multiple-choice, and dialogue, ChatQA 2 achieved an average score of 34.11, close to the highest score of 34.88 by Qwen2-72B-Instruct. The model also excels in medium-long context benchmarks within 32K tokens, scoring 47.37, and short-context tasks within 4K tokens, achieving an average score of 54.81. These results highlight ChatQA 2’s robust capabilities across different context lengths and functions.
ChatQA 2 addresses significant issues in the RAG pipeline, such as context fragmentation and low recall rates. The model improves retrieval accuracy and efficiency by utilizing a state-of-the-art long-context retriever. For example, the E5-mistral embedding model supports up to 32K tokens for retrieval, significantly enhancing the model’s performance on query-based tasks. In comparisons between RAG and long-context solutions, ChatQA 2 consistently demonstrated superior results, particularly in functions requiring extensive text processing.

In conclusion, ChatQA 2 by extending the context window to 128K tokens and implementing a three-stage instruction tuning process, ChatQA 2 achieves GPT-4-Turbo-level capabilities in long-context understanding and RAG performance. This model offers flexible solutions for various downstream tasks, balancing accuracy and efficiency through advanced long-context and retrieval-augmented generation techniques. The development and evaluation of ChatQA 2 mark a crucial step forward in large language models, providing enhanced capabilities for processing and retrieving information from extensive text inputs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post Nvidia AI Proposes ChatQA 2: A Llama3-based Model for Enhanced Long-Context Understanding and RAG Capabilities appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]