


Text retrieval is essential for applications like searching, question answering, semantic similarity, and item recommendation. Embedding or dense retrieval models play a key role in this process. The hard-negative mining method is used, to select negative passages for queries to train these models. It involves a teacher retrieval model to find passages related to the query, but not relevant compared to the positive passages, making it difficult for the model to differentiate positives from negatives. The hard-negatives method is more challenging to distinguish from the positives than the negatives. Despite its importance, hard-negative mining methods often show bad performance underexplored in text retrieval research, which typically focuses on model architectures, fine-tuning methods, and training data.
Existing methods like text embedding models turn variable-length text into fixed-size vectors. Under this, Sentence-BERT was a key development, modifying the BERT network to represent pairs of related short texts in the same space using siamese or triplet networks. Further, Contrastive learning (CL) became popular with SimCLR, which demonstrated it was more effective than classification-based losses for embeddings. Another method is hard-negative mining for fine-tuning embeddings. It selects negative passages from positive ones in the same batch, efficiently using embeddings from the training pass. However, the number of negatives is limited by the batch size, where some solutions utilize a cache or memory bank with embeddings from past batches or combining batches from different GPUs.
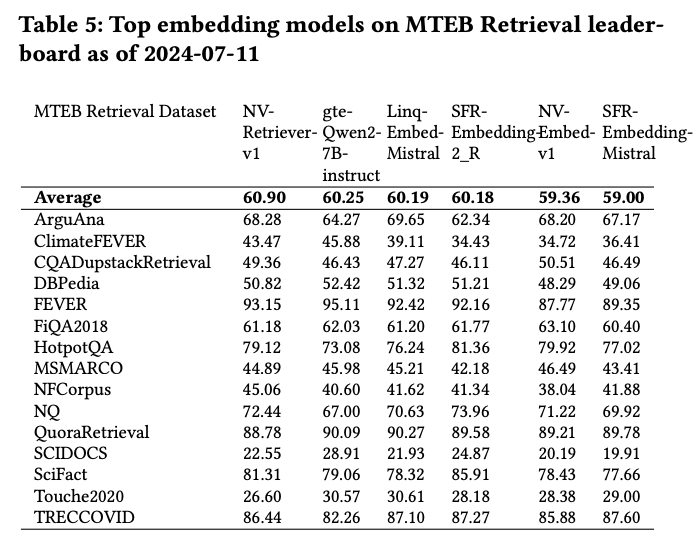
A team of researchers from NVIDIA have introduced a state-of-the-art embedding model called NV-Retriever-v1. It is a family of hard-negative mining methods that utilizes the positive relevance score, to remove false negatives more effectively. It performed exceptionally well, scoring an average of 60.9 across 15 BEIR datasets, and took first place on the MTEB Retrieval leaderboard when it was published there on July 11th, 2024. A key method for training this model is hard-negative mining, which is important for achieving top performance in text retrieval. This includes selecting the top-k most similar candidates to the query, after ignoring the positive passages, which is called Naive Top-K.
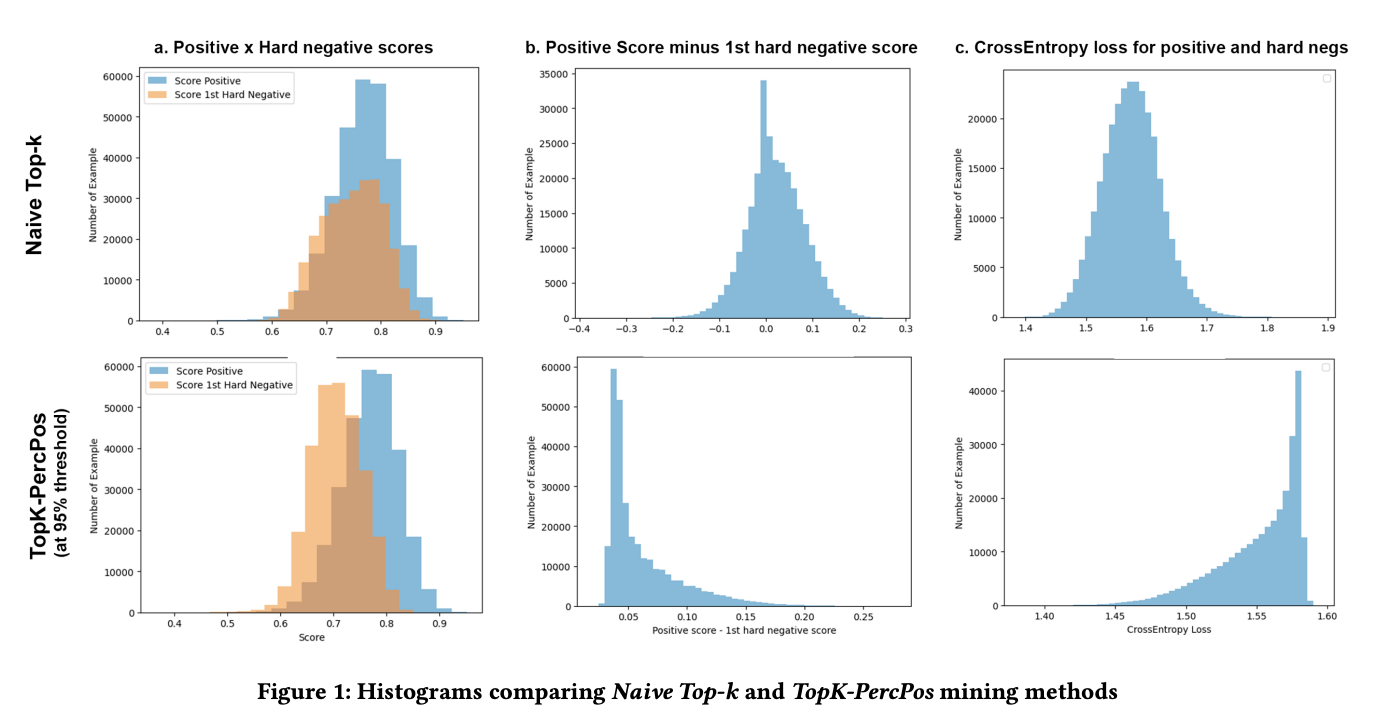
The MTEB includes tasks like retrieval, reranking, classification, and clustering, so there is a requirement for various training datasets for it to perform well. The method NV-Retriever-v1 is fine-tuned using the E5-Mistral-7B embedding model for hard-negative mining with a maximum sequence length of 4096. The proposed method, TopK-PercPos is used to avoid false negatives, setting the negative relevance score threshold at 95% of the positive score. Moreover, there are two stages of instruction tuning. In the first stage, retrieval supervised data with in-batch negatives and mined hard-negative are used. In the second stage, the data for the retrieval task is combined with datasets from other tasks.
Researchers compared negative mining methods in controlled experiments using the same hyperparameters on a subset of the BEIR datasets. NV-Retriever-v1 tests the best setup for positive-aware mining methods on the full MTEB BEIR benchmark and compares it to other top-performing models. NV-Retriever-v1 achieves an average NDCG@10 score of 60.9, placing it 1st as of July 11th, 2024. The trained NV-Retriever-v1 uses positive-aware mining methods and outperforms the best models by 0.65 points. It is a significant enhancement for the top positions on the leaderboard.
In this paper, researchers from NVIDIA have proposed NV-Retriever-v1, a state-of-the-art text embedding model. They present a detailed study comparing different methods for hard-negative mining, various teacher models, and the combination of their hard negatives, showing how these choices impact the accuracy of the fine-tuned text embedding models. At the publishing time, NV-Retriever-v1 ranked first on the MTEB Retrieval/BEIR benchmark. This study on hard-negative mining encourages further research and supports more accurate fine-tuning of text embedding models. Researchers strongly encourage future work in this area to disclose their methodology for mining, which includes specifying the teacher model and mining method used to ensure that results can be reproduced and replicated.
Check out the Paper and Model Card. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post Nvidia AI Introduces NV-Retriever-v1: An Embedding Model Optimized for Retrieval appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #ArtificialIntelligence #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]