


The quest for clean, usable data for pretraining Large Language Models (LLMs) resembles searching for treasure amidst chaos. While rich with information, the digital realm is cluttered with extraneous content that complicates the extraction of valuable data. This challenge becomes particularly pronounced when considering the vastness of the web as a data source for LLMs, which thrive on diverse and extensive datasets to enhance their linguistic capabilities.
The traditional tools for navigating this digital jungle, rule-based and heuristic web scrapers, are increasingly found wanting. Designed to parse through the HTML of webpages to fish out relevant content, these tools often need to work on the web’s complexity and constant evolution. They need help to differentiate between the core content and the myriad of distractions like advertisements, pop-ups, and irrelevant hyperlinks, leading to the collection of noisy data that can dilute the quality of LLM training sets.
NeuScraper is a novel solution crafted by researchers from Northeastern University, Tsinghua University, China Beijing National Research Center for Information Science and Technology, and Carnegie Mellon University to address this pivotal issue. NeuScraper distinguishes itself by employing a neural network-based approach to web scraping, a significant departure from the traditional methodologies. This Neural Web Scraper is adept at discerning the primary content of webpages by analyzing their structure and content through a neural lens. NeuScraper promises to enhance the efficiency of the web scraping process and significantly improve the quality of the data extracted.
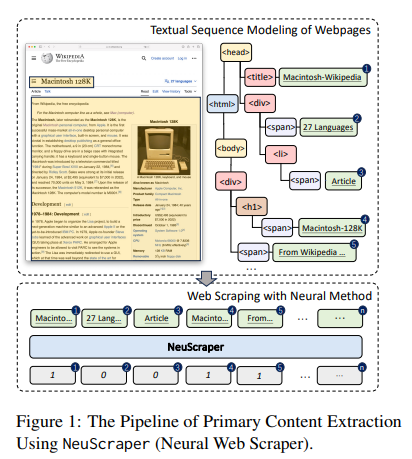
NeuScraper’s architecture begins by dissecting webpages into blocks, analyzing them through the prism of a shallow neural model that understands the webpage’s layout. This model is trained to identify and classify the primary content blocks, effectively sifting through the digital chaff to harvest the wheat. This process is underpinned by a wealth of features extracted from the blocks, ranging from linguistic to structural and visual cues, all of which feed into the neural model to facilitate the accurate identification of valuable content.

The performance of NeuScraper demonstrated a remarkable 20% improvement over existing scraping technologies, showcasing its ability to clean the noise from the data with unprecedented precision. This leap in performance is a testament to NeuScraper’s innovative approach and a beacon of potential for the future of LLM pretraining. With NeuScraper, researchers and developers can tap into the web’s vast resources more effectively, curating high-quality datasets that can drive future advancements in NLP and beyond.

In conclusion, the implications of NeuScraper’s advent are manifold:
- It heralds a new era in web scraping, where neural models unlock efficiencies and accuracies previously deemed unattainable.
- It promises a seismic shift in how data is curated for LLM pretraining, paving the way for models that are more powerful and nuanced in their understanding of language.
- By streamlining the data extraction process and enhancing the quality of datasets, NeuScraper sets the stage for a future where the potential of LLMs can be fully realized, fostering innovations that could redefine the landscape of technology and communication.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post NeuScraper: Pioneering the Future of Web Scraping for Enhanced Large Language Model Pretraining appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]