


Graph neural networks (GNNs), referred to as neural algorithmic reasoners (NARs), have shown effectiveness in robustly solving algorithmic tasks of varying input sizes, both in and out of distribution. However, NARs are still relatively narrow forms of AI as they require rigidly structured input formatting and cannot be directly applied to problems posed in noisy forms like natural language, even when the underlying problem is algorithmic. Conversely, Transformer-based language models excel at modeling noisy text data but struggle with algorithmic tasks, especially those requiring out-of-distribution generalization. The key challenge is developing methods that can handle algorithmic reasoning in natural language while maintaining strong generalization capabilities.
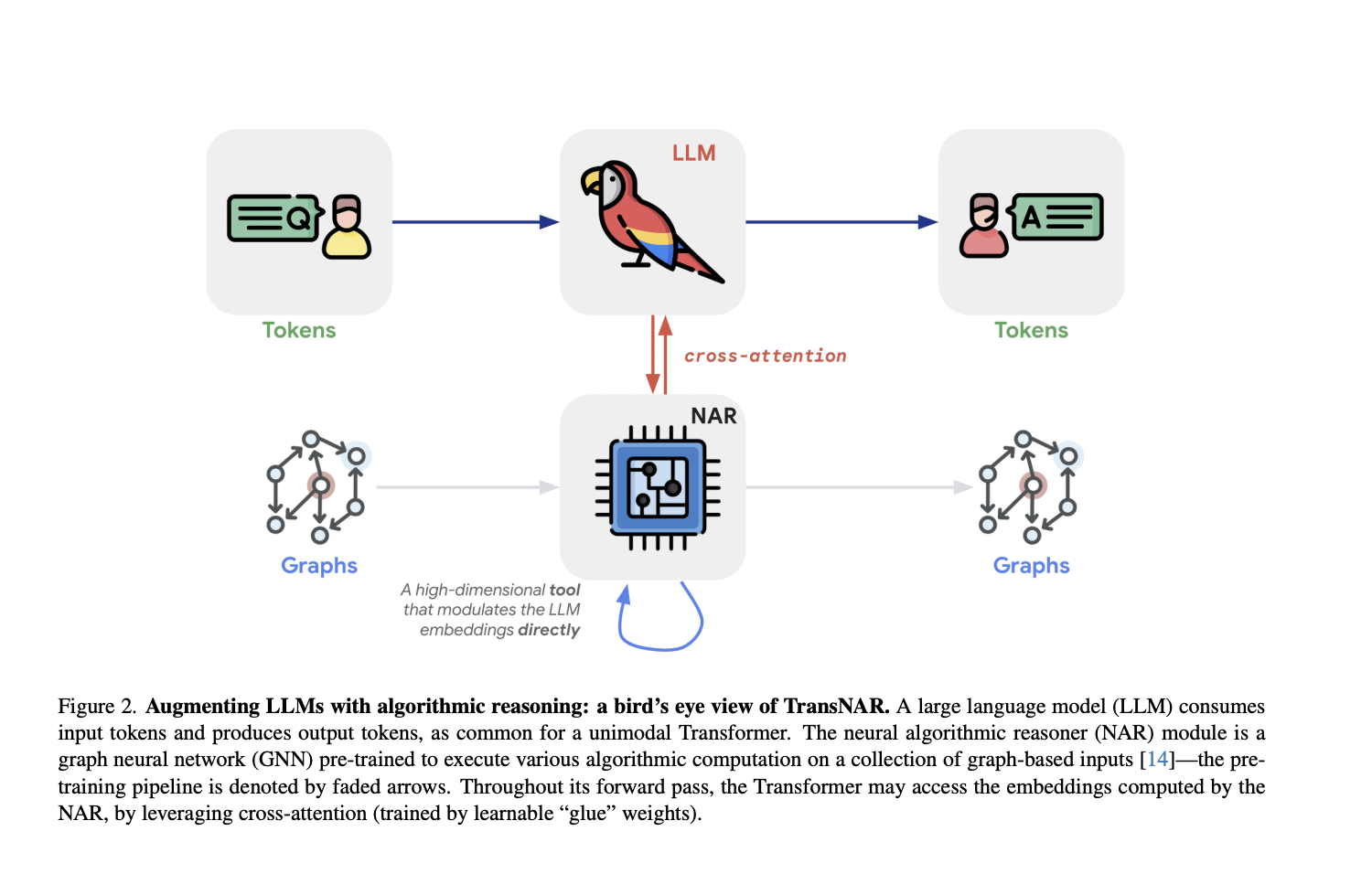
DeepMind researchers proposed TransNAR which introduces a hybrid architecture that combines the language understanding capabilities of Transformers with the robust algorithmic reasoning abilities of pre-trained GNN-based NARs. The Transformer utilizes the NAR as a high-dimensional tool to modulate its token embeddings. Specifically, the NAR module is a GNN pre-trained to execute various algorithmic computations on graph-based inputs. Throughout its forward pass, the Transformer can access the embeddings computed by the NAR by utilizing cross-attention with learnable “glue” weights. This synergy between Transformers and NARs aims to enhance the reasoning capabilities of language models, particularly for out-of-distribution algorithmic tasks.
The TransNAR method builds upon several research areas: neural algorithmic reasoning, length generalization in language models, tool use, and multimodality. It is inspired by works demonstrating that NARs can execute multiple algorithms simultaneously and generalize well beyond their training distribution. TransNAR utilizes a pre-trained multi-task NAR module and deploys it at a larger scale by integrating it with a language model. Addressing the limited length generalization capabilities of language models, TransNAR combines the language understanding of Transformers with the robust algorithmic reasoning of NARs. This hybrid approach, utilizing cross-attention between the two modules, aims to enhance reasoning abilities, especially for out-of-distribution algorithmic tasks posed in natural language.
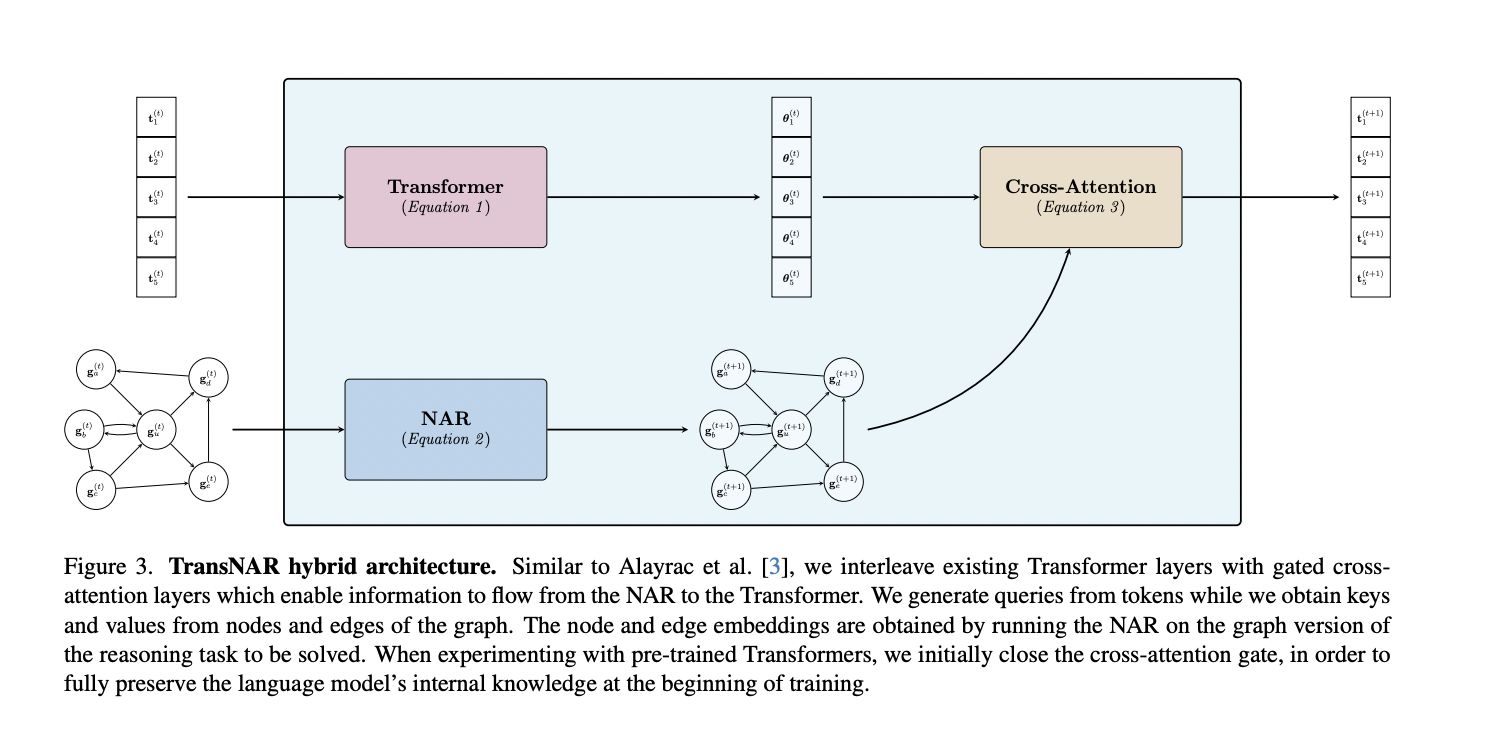
The TransNAR architecture accepts dual inputs: a textual algorithmic problem specification and its corresponding graph representation from the CLRS-30 benchmark. The model’s forward pass interleaves Transformer layers that process the textual input with NAR layers that operate on the graph input. Crucially, the Transformer layers use cross-attention to condition their token embeddings on the node embeddings computed by the NAR. This synergy enables the language model to augment its understanding with robust algorithmic reasoning capabilities from the pre-trained NAR module. The model is trained end-to-end with a next-token prediction objective on the textual output.
The results demonstrate the significant improvements achieved by the TransNAR model over the baseline Transformer. TransNAR outperforms the baseline overall and on most individual algorithms, both in-distribution and out-of-distribution. Notably, TransNAR not only enhances existing out-of-distribution generalization capabilities but also enables such capabilities when the baseline completely lacks them. The shape score analysis reveals that grounding the Transformer outputs in NAR embeddings increases the proportion of inputs for which the model produces outputs of the correct shape, alleviating a specific failure mode. However, TransNAR still struggles with algorithms involving searching for a particular index in an input list, hinting at a unified failure mode related to generalization to robust index boundaries unseen during training.

This work presents TransNAR, a hybrid architecture that combines a Transformer language model with a pre-trained graph neural network-based NAR. By grounding the language understanding capabilities of the Transformer in the robust algorithmic reasoning of the NAR, TransNAR can effectively solve algorithmic tasks specified in natural language. Evaluations on the CLRS-Text benchmark demonstrated TransNAR’s superiority over Transformer-only models, both in-distribution and crucially, in out-of-distribution regimes with larger input sizes.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post Neural Algorithmic Reasoning for Transformers: The TransNAR Framework appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]