


Large language models (LLMs) have proven their potential to handle multiple tasks and perform extremely well across various applications. However, it is challenging for LLMs to generate accurate information, especially when the knowledge is less represented in their training data. To overcome this challenge, retrieval augmentation combines information retrieval and nearest neighbor search from a non-parametric data store that improves evidence-based and situated reasoning with LLMs. This leads to a reduction tendency in semi-parametric LMs while generating unsupported content.
Many works have been explored to overcome these shortcomings. One of the existing methods is Retrieval Augmentation (RA), which uses external knowledge sources to enhance the performance of LMs in tasks that require deep understanding. Advancements in retrieval augmentation, like REALM, RAG, and Atlas, integrate the retrieval component into pre-training and fine-tuning for these downstream tasks. Another method discussed is Speculative decoding, which utilizes a small model to generate drafts for a large model. The most related method is REST which takes multiple drafts from a data store and uses a prefix trie tree to find the proposal distribution.
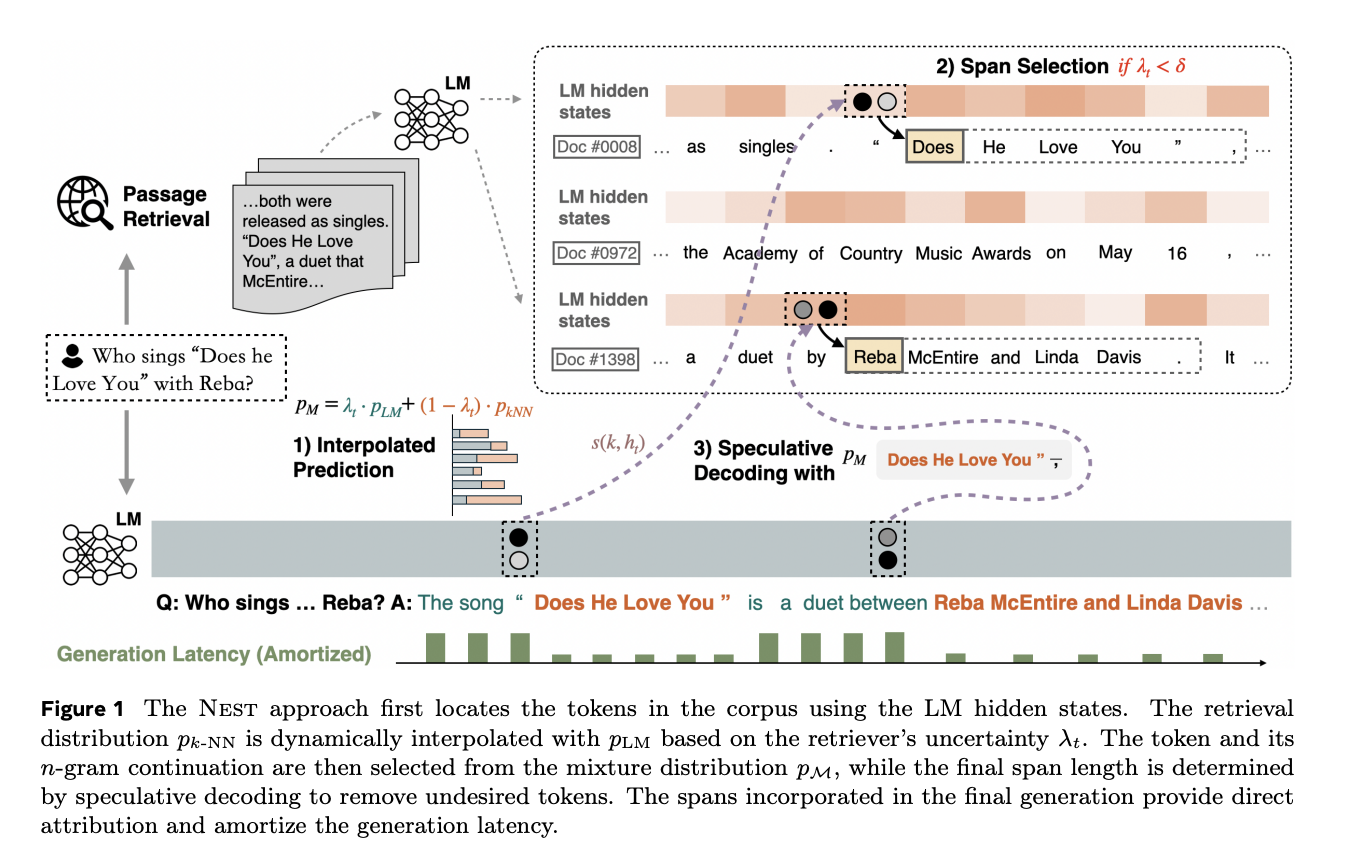
Researchers from FAIR at Meta, the University of Waterloo, Carnegie Mellon University, and the University of Chicago have proposed Nearest Neighbor Speculative Decoding (NEST). NEST is a new semi-parametric language modeling method that can integrate real-world text spans of any length into the generations of an existing LM, enhancing both the quality and latency. NEST extends the standard kNN-LM method by interpolating the output distribution of an LM with the distribution of potential next tokens derived from a corpus. Initially, it includes an extra passage retrieval step, which reduces the need to store and search through all tokens in the corpus, creating a balance between search accuracy and efficiency.
NEST generates content with three sub-steps at each inference step. These steps are:
- Confidence-based interpolation: Relative Retrieval Confidence (RRC) score is used to evaluate the uncertainty of the token retriever, which is then used as the interpolation coefficient for the output probability mixture.
- Dynamic span selection: NEST selects the best token predicted by the mixture probability and extends to include the span from that token when the threshold is exceeded by token retrieval confidence.
- Relaxed speculative decoding: When a span of multiple tokens is selected, it is evaluated based on mixture probability, and only a prefix that is highly likely according to the mixture probability is accepted.
NEST outperforms both the methods, base LM and the standard kNN-LM under a zero-shot setting using Llama-2-Chat models of different sizes on tasks such as text completion, and factuality aware generation. For example, the NEST, combined with the Llama-2-Chat 70B model, shows a 42.3% improvement of ROUGE-1 on WikiText-103 and a 21.6% improvement of FActScore on Biography. Moreover, NEST enhances the efficiency of long-form generation by producing multiple tokens at each time step, and becomes 1.8 times faster in inference time with Llama-2-Chat 70B, without affecting attribution or fluency.
In conclusion, researchers introduced NEST, an inference-time revision method for LMs that enhances their factuality and attribution with the help of nearest-neighbor speculative decoding. NEST enhances both validation perplexity and quality of free-form generation across 9 different tasks. However, some of the limitations of the proposed method are:
- The results of NEST might have factual errors depending on the accuracy of the first-stage passage retrieval and the second-stage token retrieval.
- The results can be better if fine-tuned on appropriate tasks because the integrated system without fine-tuning might be sub-optimal.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post Nearest Neighbor Speculative Decoding (NEST): An Inference-Time Revision Method for Language Models to Enhance Factuality and Attribution Using Nearest-Neighbor Speculative Decoding appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]