


Large Language Models (LLMs) have gained significant prominence in the AI industry, revolutionizing various applications such as chat, programming, and search. However, the efficient serving of multiple LLMs has emerged as a critical challenge for endpoint providers. The primary issue lies in the substantial computational requirements of these models, with a single 175B LLM demanding eight A100 (80GB) GPUs for inference. Current methodologies, particularly spatial partitioning, need to improve in resource utilization. This approach allocates separate GPU groups for each LLM, leading to underutilization due to varying model popularity and request rates. Consequently, less popular LLMs result in idle GPUs, while popular ones experience performance bottlenecks, highlighting the need for more efficient serving strategies.
Existing attempts to solve LLM serving challenges have explored various approaches. Deep learning serving systems have focused on temporal multiplexing and scheduling strategies, but these are primarily designed for smaller models. LLM-specific systems have advanced through customized GPU kernels, parallelism techniques, and optimizations like memory management and offloading. However, these methods typically target single LLM inference. GPU sharing techniques, including temporal and spatial sharing, have been developed to improve resource utilization, but they are generally tailored for smaller DNN jobs. While each approach has made contributions, they collectively fall short in addressing the unique requirements of efficiently serving multiple LLMs, highlighting the need for a more flexible and comprehensive solution.
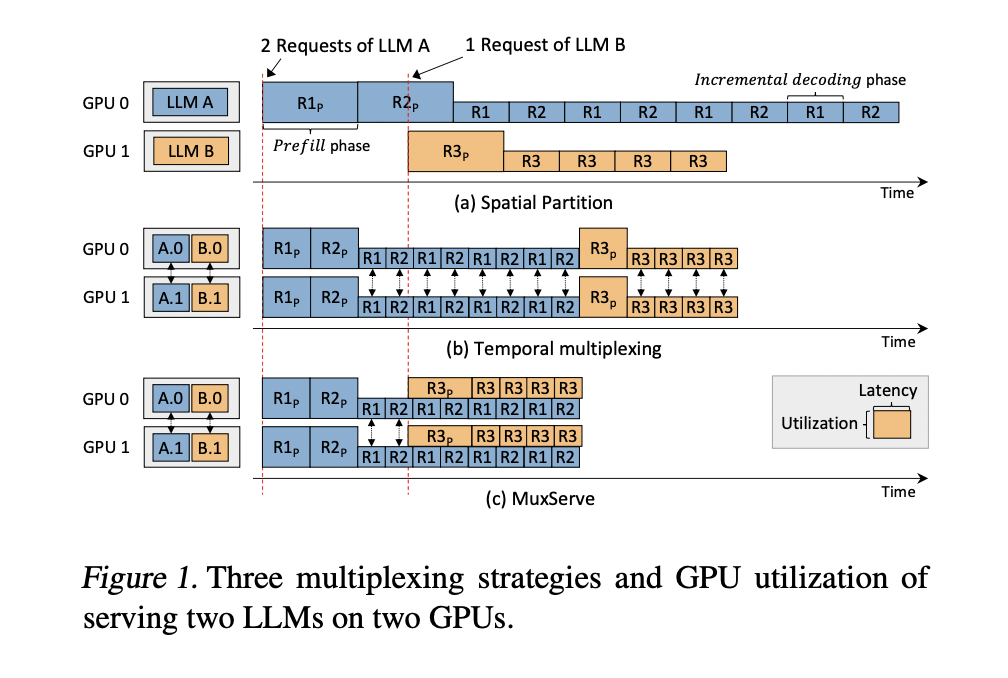
Researchers from The Chinese University of Hong Kong, Shanghai AI Laboratory, Huazhong University of Science and Technology, Shanghai Jiao Tong University, Peking University, UC Berkeley, and the UC Sandiego present MuxServe, a flexible spatial-temporal multiplexing approach for serving multiple LLMs, addressing GPU utilization challenges. It separates prefill and incremental decoding phases colocates jobs based on LLM popularity, and employs an optimization framework to determine ideal resource allocation. The system uses a greedy placement algorithm, adaptive batch scheduling, and a unified resource manager to maximize efficiency. By partitioning GPU SMs with CUDA MPS, MuxServe achieves effective spatial-temporal partitioning. This approach results in up to 1.8× higher throughput than existing systems, marking a significant advancement in efficient multi-LLM serving.
MuxServe introduces a flexible spatial-temporal multiplexing approach for serving multiple LLMs efficiently. The system formulates an optimization problem to find the best group of LLM units that maximize GPU utilization. It employs an enumeration-based greedy algorithm for LLM placement, prioritizing models with larger computational requirements. To maximize intra-unit throughput, MuxServe uses an adaptive batch scheduling algorithm that balances prefill and decoding jobs while ensuring fair resource sharing. A unified resource manager enables efficient multiplexing by dynamically allocating SM resources and implementing a head-wise cache for shared memory usage. This comprehensive approach allows MuxServe to effectively colocate LLMs with varying popularity and resource needs, improving overall system utilization.
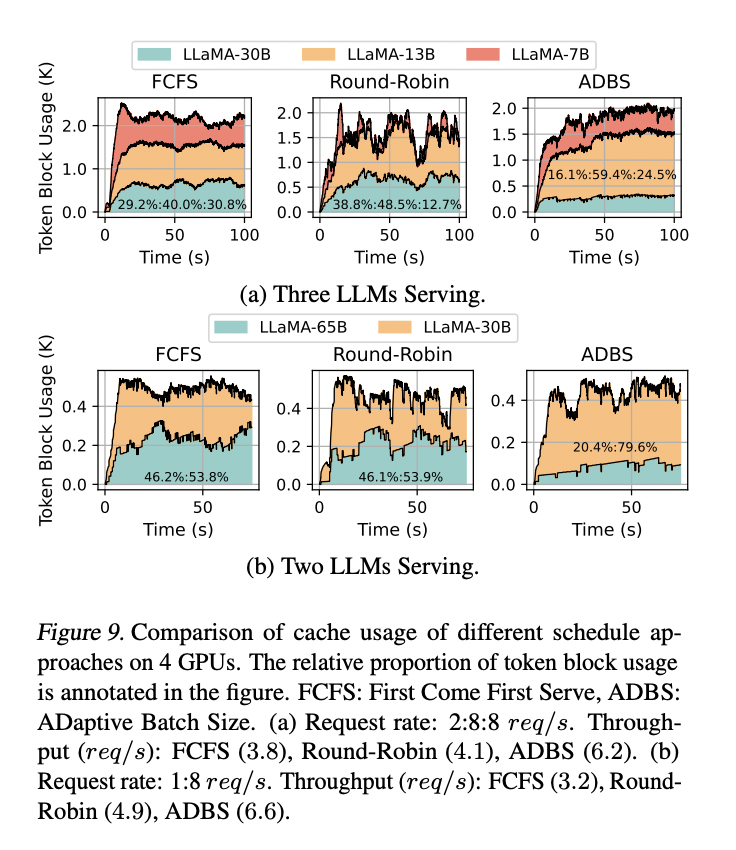
MuxServe demonstrates superior performance in both synthetic and real-world workloads. In synthetic scenarios, it achieves up to 1.8× higher throughput and processes 2.9× more requests within 99% SLO attainment compared to baseline systems. The system’s efficiency varies with workload distribution, showing particular strength when LLM popularity is diverse. In real workloads derived from ChatLMSYS traces, MuxServe outperforms spatial partitioning and temporal multiplexing by 1.38× and 1.46× in throughput, respectively. It consistently maintains higher SLO attainment across various request rates. The results highlight MuxServe’s ability to efficiently colocate LLMs with different popularity levels, effectively multiplexing resources and improving overall system utilization.
This study introduces MuxServe representing a significant advancement in the field of LLM serving. By introducing flexible spatial-temporal multiplexing, the system effectively addresses the challenges of serving multiple LLMs concurrently. Its innovative approach of colocating LLMs based on their popularity and separating prefill and decoding jobs leads to improved GPU utilization. This method demonstrates substantial performance gains over existing systems, achieving higher throughput and better SLO attainment across various workload scenarios. MuxServe’s ability to adapt to different LLM sizes and request patterns makes it a versatile solution for the growing demands of LLM deployment. As the AI industry continues to evolve, MuxServe provides a promising framework for efficient and scalable LLM serving.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post MuxServe: A Flexible and Efficient Spatial-Temporal Multiplexing System to Serve Multiple LLMs Concurrently appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]