


Navigating the intricate landscape of generative AI, particularly in the text-to-image (T2I) synthesis domain, presents a formidable challenge: accurately generating images depicting multiple objects, each with specific spatial relationships and attributes. Despite their remarkable capabilities, traditional state-of-the-art models, such as Stable Diffusion and DALL-E 3, often stumble when faced with complex prompts requiring precise control over multiple objects’ spatial arrangement and interaction.
This gap in the technology’s ability to interpret and visually render detailed textual descriptions has prompted a team of researchers from the Hong Kong University of Science and Technology, the University of California Los Angeles, Penn State University, and the University of Maryland to develop a groundbreaking solution: MuLan, a multimodal-LLM agent.
MuLan revolutionizes generating images from the text by adopting a strategy reminiscent of a human artist’s method. At its core, MuLan utilizes a large language model (LLM) to dissect a complex prompt into manageable sub-tasks, each dedicated to generating one object about those previously created. This sequential generation process allows for meticulous control over each object’s spatial positioning and attributes, effectively addressing the limitations of existing T2I models. MuLan employs a vision-language model (VLM) to provide critical feedback, correcting any deviations from the original prompt in real time. This innovative feedback loop ensures that the generated images closely align with the textual descriptions, enhancing the accuracy and fidelity of the output.
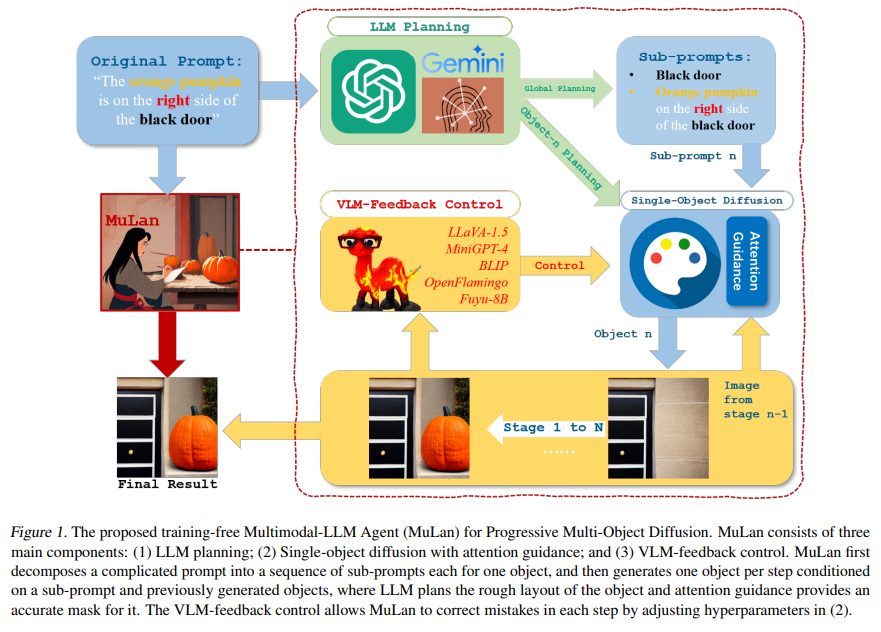
The evaluation of MuLan’s performance involved a comprehensive dataset of prompts, encompassing many objects, spatial relationships, and attributes. The results were unequivocal, demonstrating MuLan’s superior capability in handling complex image generation tasks with remarkable precision. Compared to baseline models, MuLan consistently outperformed in metrics such as object completeness, attribute accuracy, and the maintenance of spatial relationships. These findings highlight MuLan’s potential to redefine standards in generative AI and underscore the model’s ability to bridge the gap between textual prompts and their visual representations.

MuLan signifies a pivotal advancement in the field of T2I synthesis, offering a novel and effective solution to the challenges of generating detailed, multi-object images from text. By mimicking the iterative and corrective processes employed by human artists, MuLan opens new horizons for AI-driven creative endeavors. The implications of this technology extend far beyond the immediate benefits of enhanced image generation, promising to catalyze innovation across a broad spectrum of applications in digital art, design, and multimedia content creation.
In conclusion, the research can be summarized as follows:
- MuLan is a groundbreaking step in generative AI for T2I synthesis, addressing the challenge of complex prompts.
- It leverages an LLM for task decomposition and a VLM for feedback, ensuring high fidelity to prompts.
- Superior performance in object completeness, attribute accuracy, and spatial relationships.
- Potential applications span digital art, design, and beyond, highlighting MuLan’s versatile impact.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post MuLan: Pioneering Precision in Text-to-Image Synthesis with Progressive Multi-Object Generation appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]