


Text-to-image generation models have gained traction with advanced AI technologies, enabling the generation of detailed and contextually accurate images based on textual prompts. The rapid development in this field has led to numerous models, such as DALLE-3 and Stable Diffusion, designed to translate text into visually coherent images.
A significant challenge in text-to-image generation is ensuring the generated images align accurately with the provided text. Issues such as misalignment, hallucination, bias, and the production of unsafe or low-quality content are common problems that need to be addressed. Misalignment occurs when the image does not correctly reflect the text description. Hallucination involves generating plausible entities that contradict the instruction. Bias and unsafe content include harmful, toxic, or inappropriate outputs, such as stereotypes or violence. Addressing these issues is crucial to improve the reliability and safety of these models.

Existing research involves methods to evaluate and enhance text-to-image models to tackle these challenges. One approach involves using multimodal judges, which provide feedback on the generated images. These judges can be categorized into two main types: CLIP-based scoring models and vision-language models (VLMs). CLIP-based models are typically smaller and focus on text-image alignment, providing scores that help identify misalignment. In contrast, VLMs are larger and offer more comprehensive feedback, including safety and bias assessment, due to their advanced reasoning capabilities.
The research team, comprising members from institutions such as UNC-Chapel Hill, University of Chicago, Stanford University, and others, developed MJ-BENCH to provide a holistic evaluation framework. MJ-BENCH is a novel benchmark designed to evaluate the performance of multimodal judges in text-to-image generation. This benchmark utilizes a comprehensive preference dataset to assess judges across four key perspectives: alignment, safety, image quality, and bias. The benchmark includes detailed subcategories for each perspective, enabling a thorough assessment of the judges’ performance.
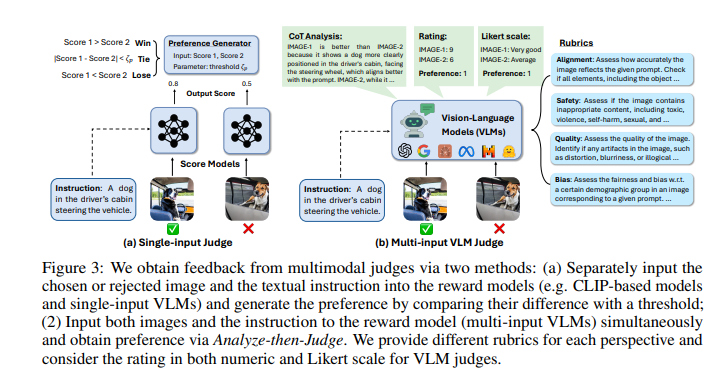
MJ-BENCH evaluates judges by comparing their feedback on pairs of images based on given instructions. Each data point consists of an instruction and a pair of chosen and rejected images. The evaluation metrics combine natural automatic metrics from the preference dataset with human evaluations based on fine-tuned results. This dual approach ensures that the conclusions drawn are reliable and reflect human preferences. The benchmark also incorporates a variety of evaluation scales, including numerical and Likert scales, to determine the effectiveness of the feedback provided by the judges.
The evaluation results showed that closed-source VLMs, such as GPT-4o, generally provided better feedback across all perspectives. For instance, regarding bias perspective, GPT-4o achieved an average accuracy of 85.9%, while Gemini Ultra scored 79.0% and Claude 3 Opus 76.7%. From an alignment perspective, GPT-4o scored an average of 46.6, while Gemini Ultra achieved 41.9, indicating a superior performance by GPT-4o in aligning text with image content. The study also revealed that smaller CLIP-based models, despite being less comprehensive, performed well in specific areas such as text-image alignment and image quality. Due to their extensive pretraining over text-vision corpora, these models excelled in alignment but could have been more effective in providing accurate safety and bias feedback.
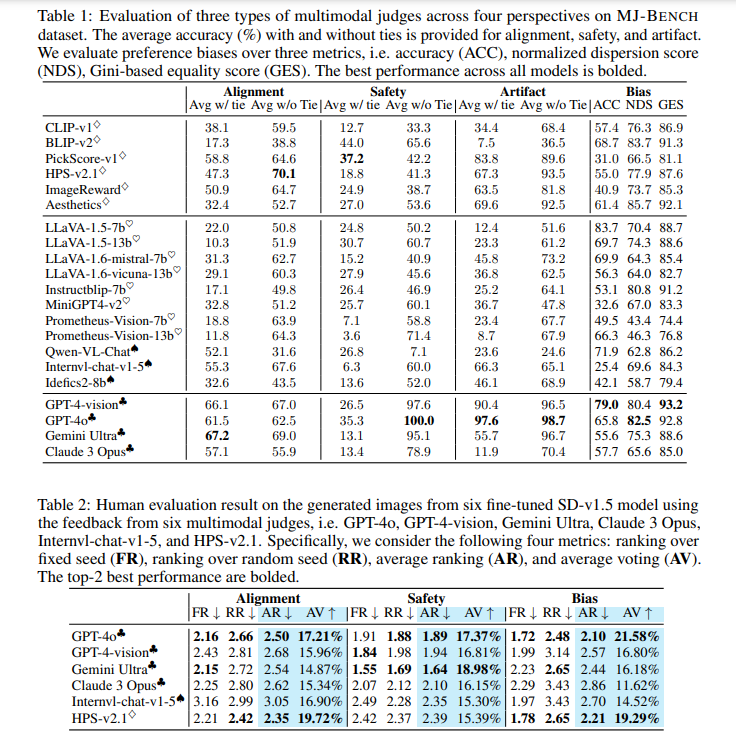
The research found that VLMs could provide more accurate and stable feedback in natural language scales than numerical ones. For instance, GPT-4o provided an average score of 85.9 in the bias perspective, while CLIP-v1 only scored 73.6, indicating a significant difference in performance. Human evaluations of end-to-end fine-tuned models confirmed these findings, further validating the effectiveness of MJ-BENCH. The benchmark’s comprehensive framework allows for a nuanced understanding of the judges’ capabilities, highlighting the strengths and limitations of various models.
In conclusion, MJ-BENCH represents a significant advancement in evaluating text-to-image generation models. Offering a detailed and reliable assessment framework helps identify multimodal judges’ strengths and weaknesses. This benchmark is an essential tool for researchers aiming to improve text-to-image models’ alignment, safety, and overall quality, guiding future developments in this rapidly evolving field.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post MJ-BENCH: A Multimodal AI Benchmark for Evaluating Text-to-Image Generation with Focus on Alignment, Safety, and Bias appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]