


The interdisciplinary domain of vision-language representation seeks innovative methods to develop systems to understand the nuanced interactions between text and images. This area is pivotal as it enables machines to process and interpret the vast amount of digitally available visual and textual content. Despite significant advances, the challenge persists primarily due to the noisy data sourced from the internet, where image-caption pairs often do not align well, leading to inaccuracies in training models.
Researchers from FAIR at Meta, Columbia University, New York University, and the University of Washington present a new approach known as the Mixture of Data Experts (MoDE). This approach revolutionizes handling noisy datasets by segmenting the training data into distinct clusters. Unlike traditional methods that train a single model on all data, MoDE assigns a dedicated ‘data expert’ to each cluster. These experts specialize in specific data subsets, enhancing the model’s robustness against the noise in unrelated segments.
MoDE’s strategy involves two main steps. Initially, the data, comprising image-caption pairs, is clustered based on semantic similarity, ensuring that each cluster contains closely related examples. Each cluster then trains a separate data expert using standard contrastive learning techniques. This specialization allows each expert to develop a nuanced understanding of its specific data cluster without the interference of noise from other clusters.
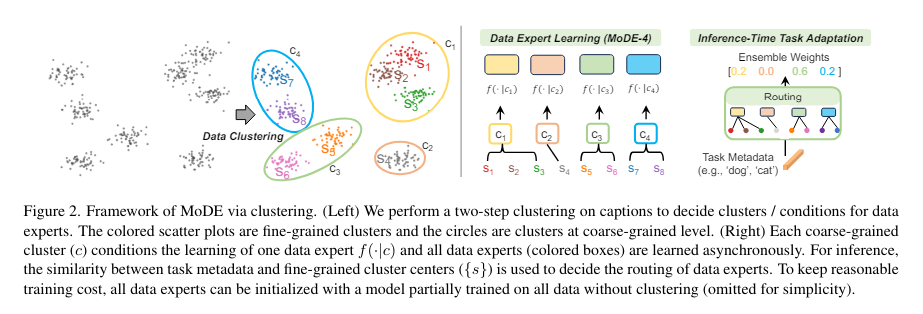
The operational effectiveness of MoDE is evident during the inference phase, where the outputs from various data experts are ensembled. This ensemble is not arbitrary but guided by the task metadata, which correlates with the conditions of each cluster, thus selecting the most relevant experts for the task. For example, in image classification tasks, the class names are compared against the centroids of the data clusters to determine the most applicable data expert, ensuring precision in the model’s output.
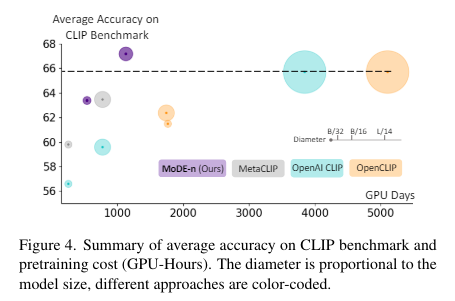
When tested across multiple benchmarks, MoDE-equipped models consistently outperformed existing state-of-the-art vision-language models. Notably, on zero-shot image classification tasks, MoDE’s data experts operating on a ViT-B/16 architecture achieved a performance boost of up to 3.7% over traditional models like OpenAI CLIP and OpenCLIP while requiring less than 35% of the training resources typically consumed by these models. Further, MoDE demonstrated significant improvements in image-to-text and text-to-image retrieval tasks on datasets such as COCO, which improved recall metrics by over 3% compared to baseline models.
In conclusion, the Mixture of Data Experts (MoDE) method represents a paradigm shift in managing noisy training data in vision-language representation. By leveraging clustered data handling and specialized data experts, MoDE improves the accuracy and efficiency of the training process. It enhances the model’s applicability to various tasks without extensive retraining. Its ability to perform well across different datasets and tasks with reduced computational requirements suggests that MoDE could be a sustainable and scalable model for future vision-language processing challenges. This strategic shift towards using multiple specialized experts in place of a singular model addresses the core challenges of noise and data heterogeneity effectively, setting a new benchmark for the field.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post Mixture of Data Experts (MoDE) Transforms Vision-Language Models: Enhancing Accuracy and Efficiency through Specialized Data Experts in Noisy Environments appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]