


Machine learning, particularly deep neural networks, focuses on developing models that accurately predict outcomes and quantify the uncertainty associated with those predictions. This dual focus is especially important in high-stakes applications such as healthcare, medical imaging, and autonomous driving, where decisions based on model outputs can have profound implications. Accurate uncertainty estimation helps assess the risk associated with utilizing a model’s predictions, determining when to trust a model’s decision and when to override it, which is crucial for safe deployment in real-world scenarios.
This research addresses the primary issue of ensuring model reliability and proper calibration under distribution shifts. Traditional methods for uncertainty estimation in machine learning models often rely on Bayesian principles, which involve defining a prior distribution and sampling from a posterior distribution. However, these methods encounter significant challenges in modern deep learning due to the difficulty in specifying appropriate priors and the scalability issues inherent in Bayesian approaches. These limitations hinder the practical application of Bayesian methods in large-scale deep-learning models.
Current approaches to uncertainty estimation include various Bayesian methods and the Minimum Description Length (MDL) principle. Although theoretically sound, Bayesian methods require extensive computational resources and face challenges defining suitable priors for complex models. The MDL principle offers an alternative by minimizing the combined codelength of models and observed data, thereby avoiding the need for explicit priors. However, the practical implementation of MDL, particularly through the predictive normalized maximum likelihood (pNML) distribution, is computationally intensive. Calculating the pNML distribution involves optimizing a hindsight-optimal model for each possible label, which is infeasible for large-scale neural networks.
The Massachusetts Institute of Technology, University of Toronto, and Vector Institute for Artificial Intelligence research team introduced IF-COMP, a scalable and efficient approximation of the pNML distribution. This method leverages a temperature-scaled Boltzmann influence function to linearize the model, producing well-calibrated predictions and measuring complexity in labeled and unlabeled settings. The IF-COMP method regularizes the model’s response to additional data points by applying a proximal objective that penalizes movement in function and weight space. IF-COMP softens the local curvature by incorporating temperature scaling, allowing the model to accommodate low-probability labels better.
The IF-COMP method first defines a temperature-scaled proximal Bregman objective to reduce model overconfidence. This involves linearizing the model with a Boltzmann influence function, approximating the hindsight-optimal output distribution. The resulting complexity measure and associated pNML code enable the generation of calibrated output distributions and the estimation of stochastic complexity for both labeled and unlabeled data points. Experimental validation of IF-COMP was conducted on tasks such as uncertainty calibration, mislabel detection, and out-of-distribution (OOD) detection. In these tasks, IF-COMP consistently matched or outperformed strong baseline methods.
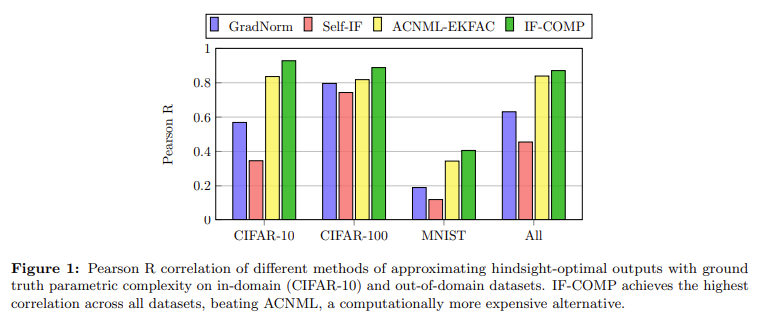
Performance evaluation of IF-COMP revealed significant improvements over existing methods. For example, in uncertainty calibration on CIFAR-10 and CIFAR-100 datasets, IF-COMP achieved lower expected calibration error (ECE) across various corruption levels than Bayesian and other NML-based methods. Specifically, IF-COMP provided a 7-15 times speedup in computational efficiency compared to ACNML. In mislabel detection, IF-COMP demonstrated strong performance with an area under the receiver operating characteristic curve (AUROC) of 96.86 for human noise on CIFAR-10 and 95.21 for asymmetric noise on CIFAR-100, outperforming methods like Trac-IN, EL2N, and GraNd.
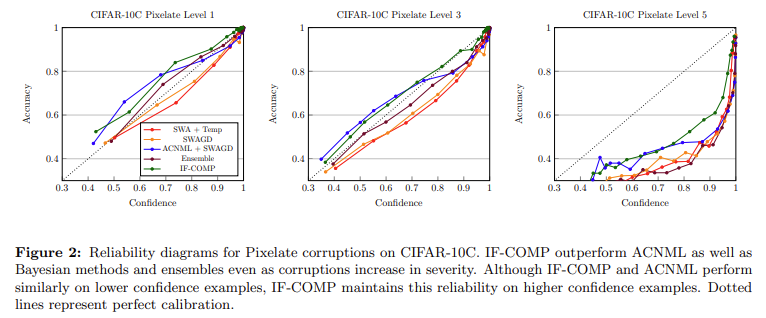
IF-COMP achieved state-of-the-art results in OOD detection tasks. On the MNIST dataset, IF-COMP attained an AUROC of 99.97 for far-OOD datasets, significantly outperforming all 20 baseline methods in the OpenOOD benchmark. On CIFAR-10, IF-COMP set a new standard with an AUROC of 95.63 for far-OOD datasets. These results underscore IF-COMP’s effectiveness in providing calibrated uncertainty estimates and detecting mislabeled or OOD data.

In conclusion, the IF-COMP method significantly advances uncertainty estimation for deep neural networks. By efficiently approximating the pNML distribution using a temperature-scaled Boltzmann influence function, IF-COMP addresses the computational challenges of traditional Bayesian and MDL approaches. The method’s strong performance across various tasks, including uncertainty calibration, mislabel detection, and OOD detection, highlights its potential for enhancing the reliability and safety of machine learning models in real-world applications. The research demonstrates that MDL-based approaches, when implemented effectively, can provide robust and scalable solutions for uncertainty estimation in deep learning.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post MIT Researchers Propose IF-COMP: A Scalable Solution for Uncertainty Estimation and Improved Calibration in Deep Learning Under Distribution Shifts appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #DeepLearning #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]