


Vision Language Models (VLMs) emerge as a result of a unique integration of Computer Vision (CV) and Natural Language Processing (NLP). This integration seeks to mimic human-like understanding by interpreting and generating content that marries images with words, giving rise to a complex challenge that has piqued the interest of researchers worldwide.
Recent developments have introduced models like LLaVA and BLIP-2, which capitalize on massive collections of image-text pairs to fine-tune cross-modal alignment. Advancements like LLaVA-Next and Otter-HD have focused on enhancing image resolution and token quality, enriching visual embeddings within LLMs, and addressing the computational challenges of processing high-resolution images. Moreover, methods such as InternLM-XComposer and auto-regressive token prediction approaches, exemplified by EMU and SEED, have sought to enable LLMs to decode images directly through extensive image-text data. While effective, these approaches have faced challenges related to latency and the need for massive training resources.
Researchers from the Chinese University of Hong Kong and SmartMore have introduced a novel framework, Mini-Gemini, that advances VLMs by enhancing multi-modal input processing. Its distinctiveness lies in employing a dual-encoder system and a novel patch info mining technique alongside a specially curated high-quality dataset. These innovations enable Mini-Gemini to process high-resolution images effectively and generate context-rich visual and textual content, setting it apart from existing models.
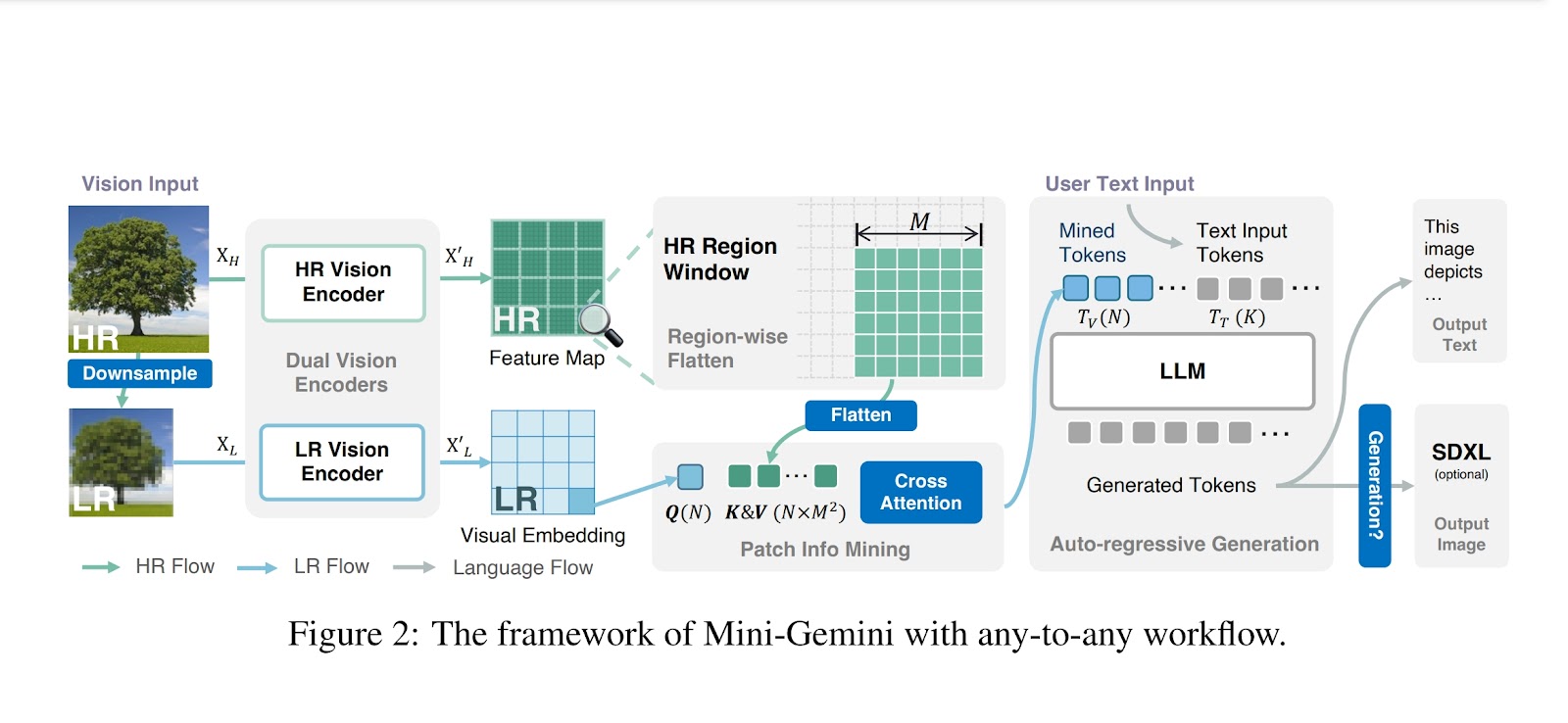
The methodology behind Mini-Gemini involves a dual-encoder system that includes a convolutional neural network for refined image processing, enhancing visual tokens without increasing their number. It utilizes patch info mining for detailed visual cue extraction. The framework is trained on a composite dataset, combining high-quality image-text pairs and task-oriented instructions to improve model performance and application scope. Mini-Gemini is compatible with various Large Language Models (LLMs), ranging from 2B to 34B parameters, enabling efficient any-to-any inference. This setup allows Mini-Gemini to achieve superior results in zero-shot benchmarks and supports advanced multi-modal tasks.
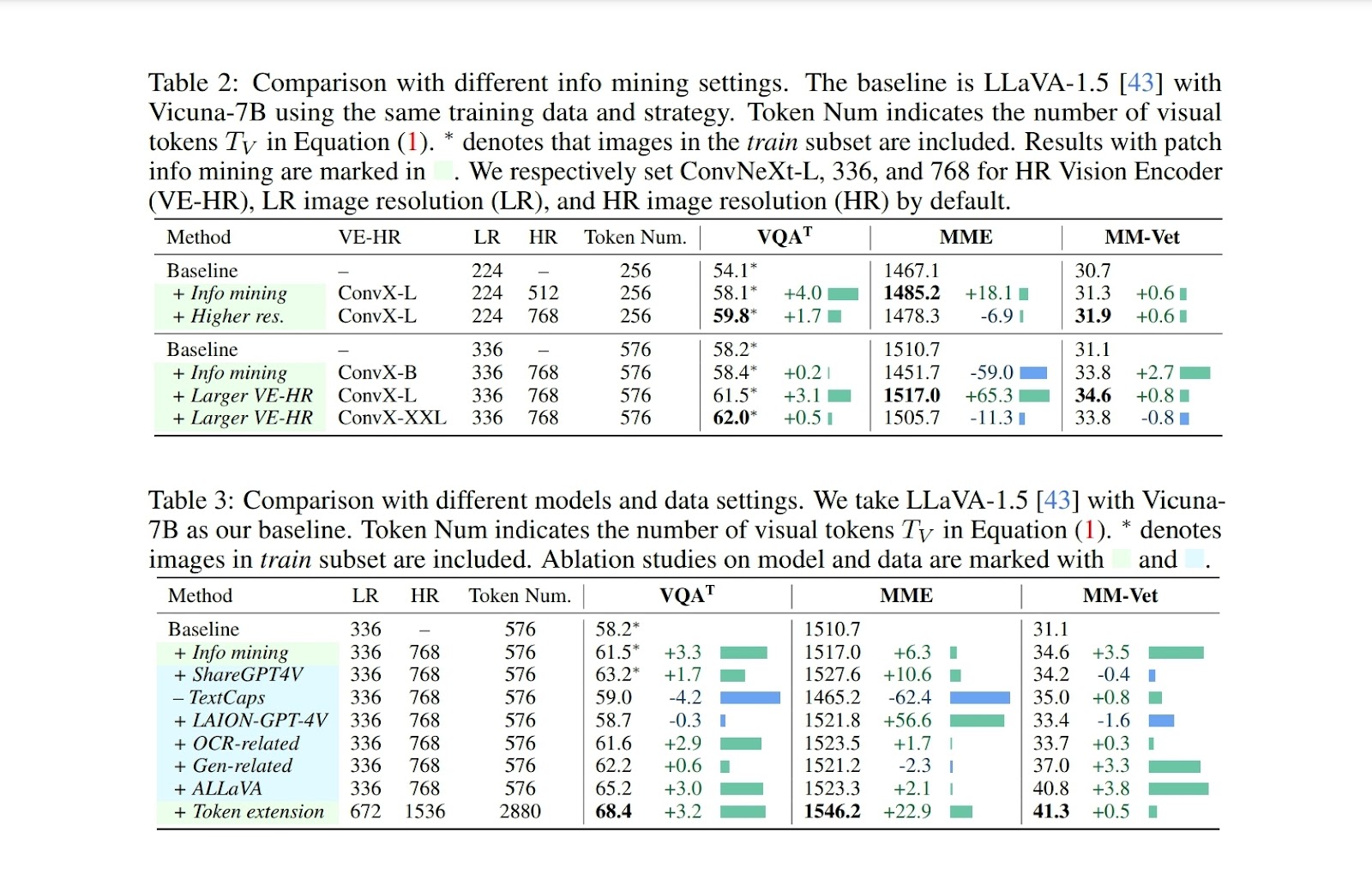
In evaluating Mini-Gemini’s effectiveness, the framework showcased leading performance in several zero-shot benchmarks. Specifically, it surpassed the Gemini Pro model in the MM-Vet and MMBench benchmarks, scoring 79.6 and 75.6, respectively. When configured with Hermes-2-Yi-34B, Mini-Gemini achieved a remarkable 70.1 score in the VQAT benchmark, outperforming the existing LLaVA-1.5 model across all evaluated metrics. These results validate Mini-Gemini’s advanced multi-modal processing capabilities, highlighting its efficiency and precision in handling complex visual and textual tasks.
To conclude, the research introduces Mini-Gemini, which advances VLMs through a dual-encoder system, patch info mining, and a high-quality dataset. Demonstrating exceptional performance across multiple benchmarks, Mini-Gemini outperforms established models, marking a significant step forward in multi-modal AI capabilities. However, as the researchers acknowledge, there is still room for improvement in Mini-Gemini’s visual comprehension and reasoning abilities, and they assert that future work will explore advanced methods for visual understanding, reasoning, and generation.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post Mini-Gemini: A Simple and Effective Artificial Intelligence Framework Enhancing multi-modality Vision Language Models (VLMs) appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]