


Text-to-speech (TTS) synthesis focuses on converting text into spoken words with a high degree of naturalness and intelligibility. This field intersects with natural language processing, speech signal processing, and machine learning. TTS technology has become integral in various applications such as virtual assistants, audiobooks, and accessibility tools, aiming to create systems that can generate speech indistinguishable from human voices.
One significant challenge in TTS synthesis is achieving high-quality, natural-sounding speech that can handle diverse voices and accents. Traditional TTS methods often need help with the variability in speaker voices and require extensive training data. This limitation hinders the scalability and flexibility of TTS systems, particularly in zero-shot learning scenarios where the system must generate speech for unseen speakers or languages without prior training data.
Current research includes neural network-based TTS approaches like sequence-to-sequence models and variational autoencoders. Using neural codec language modeling, VALL-E leverages discrete codec codes for TTS tasks. Other works include Voicebox and Audiobox using flow-matching methods and NaturalSpeech 3 with diffusion models. These methods enhance speech quality and variability but face efficiency and data requirements challenges, especially in zero-shot learning scenarios where the model must generate speech for unseen speakers or languages.
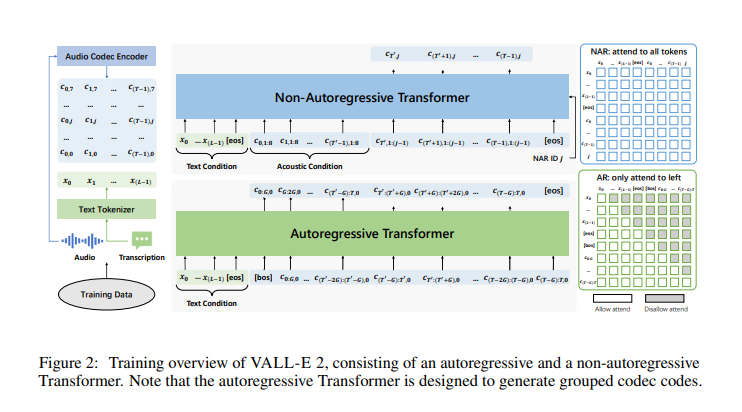
Researchers from Microsoft have introduced VALL-E 2, a novel approach leveraging neural codec language modeling inspired by the success of large language models in text processing. This method represents speech as discrete codec codes and approaches TTS as a conditional codec language modeling task. VALL-E 2 incorporates two key enhancements: repetition-aware sampling and grouped code modeling. These innovations aim to enhance zero-shot TTS capabilities using a versatile and efficient model structure.
VALL-E 2 uses a two-stage approach involving autoregressive (AR) and non-autoregressive (NAR) models. The AR model predicts a sequence of codec codes using nucleus sampling with repetition-aware techniques, ensuring stability and diversity in speech output. The NAR model generates the remaining codes, improving efficiency and robustness. Repetition-aware sampling adaptively employs random or nucleus sampling for each token prediction based on the token’s repetition in the decoding history. Grouped code modeling partitions codec codes into groups, each modeled as a single frame, reducing sequence length and enhancing performance.
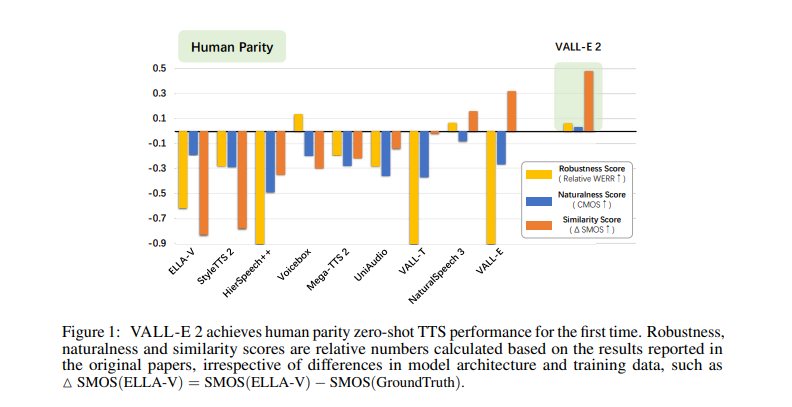
Performance evaluations of VALL-E 2 demonstrate significant improvements in zero-shot TTS scenarios. The model was trained on the Libriheavy dataset and evaluated on the LibriSpeech and VCTK datasets. It achieved human parity regarding robustness, naturalness, and similarity scores. On the LibriSpeech dataset, VALL-E 2 achieved a Word Error Rate (WER) of 4.2% for 3-second prompts and 3.8% for 5-second prompts, compared to the ground truth WER of 4.5%. The similarity score (SIM) for VALL-E 2 was 0.803 with single sampling and improved to 0.807 with five-time sampling, indicating highly accurate and natural speech synthesis. In the VCTK dataset, the model achieved a robustness score of 0.3 and a naturalness score of 4.47 for 3-second prompts, demonstrating its superior performance in diverse speaker scenarios.
The methodology of VALL-E 2 is detailed and robust. The AR model is trained to predict the first codec code sequence conditioned on the text sequence in an autoregressive manner. The NAR model, on the other hand, predicts subsequent codec codes based on the initial AR model’s output, leveraging text and acoustic conditions. This two-stage approach ensures both stability and efficiency in generating high-quality speech. The repetition-aware sampling method significantly enhances decoding stability, while grouped code modeling addresses the long context modeling problem by reducing the sequence length and improving inference efficiency.
In conclusion, VALL-E 2 addresses critical challenges in TTS synthesis by introducing a novel codec language modeling approach. This method enhances zero-shot learning capabilities, offering high-quality, natural speech synthesis with improved efficiency and robustness. The research conducted by Microsoft marks a significant step forward in developing scalable and flexible TTS systems capable of synthesizing speech for diverse applications. The advancements in VALL-E 2 could support initiatives such as generating speech for individuals with speech impairments, enhancing virtual assistants, and more.
just the first few tokens.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post Microsoft Researchers Introduce VALL-E 2: A Language Modeling Approach that Achieves Human Parity Zero-Shot Text-to-Speech Synthesis (TTS) appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]