


LLMs have grown remarkably over the past few years, largely driven by global initiatives to scale up both model sizes and datasets. From just one billion parameters five years ago, exemplified by GPT-2 with 1.5 billion parameters, LLMs now boast trillion-parameter architectures. This push stems from the perceived benefits of training larger models, as indicated by scaling laws. However, these laws traditionally presuppose a static data source, a notion challenged by the emergence of cutting-edge LLMs, enabling novel interactions with data.
Previous research on the phi models demonstrated that combining LLM-based web data filtering with LLM-generated synthetic data yields performance levels typically associated with much larger models. For instance, phi-2, with 2.7 billion parameters, matched the performance of models 25 times its size trained on conventional data.
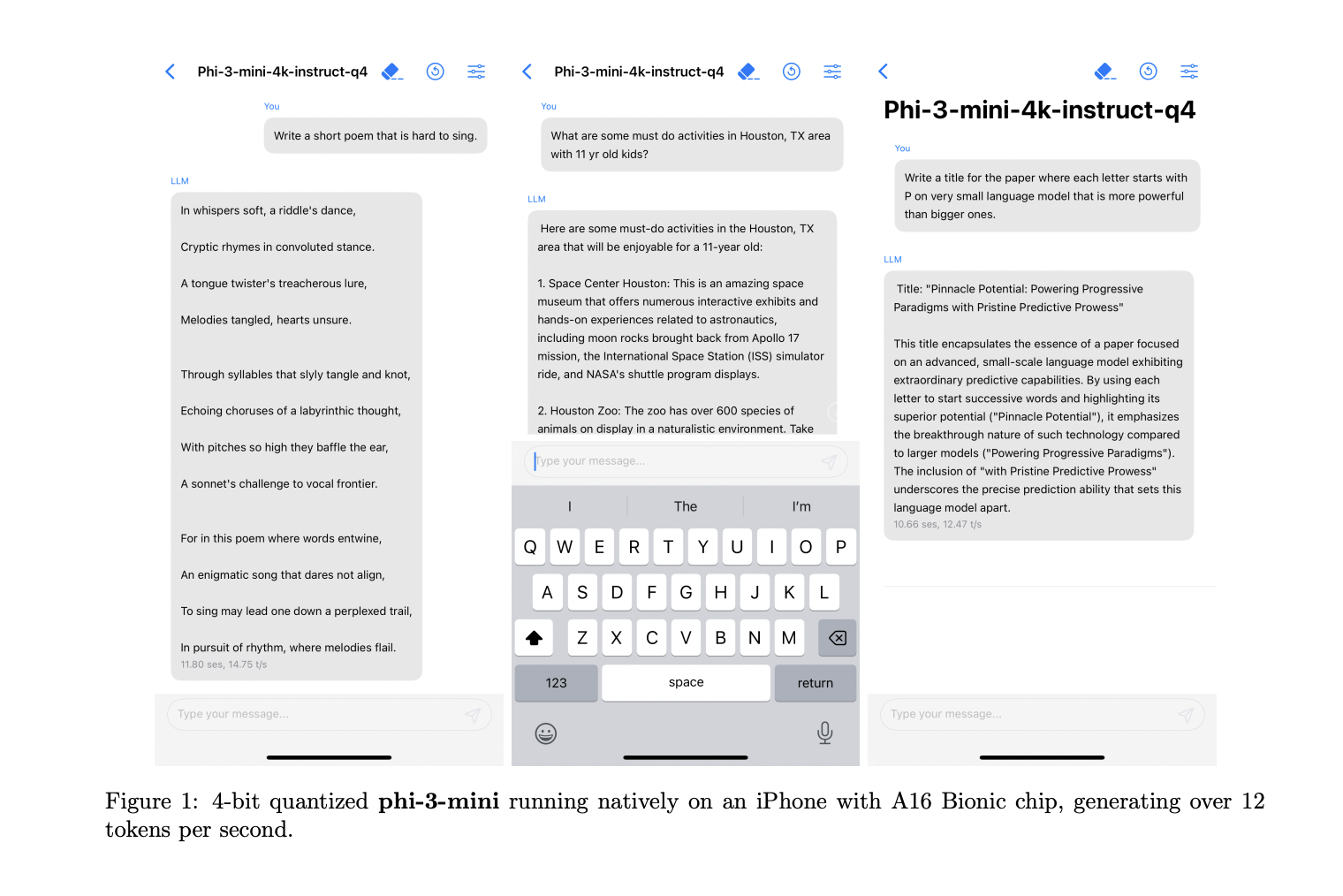
Microsoft researchers introduced phi-3-mini, a new model with 3.8 billion parameters, trained on enhanced datasets exceeding 3.3 trillion tokens. Despite its smaller size, the phi-3-mini facilitates local inference on contemporary smartphones. The model adopts a transformer decoder architecture with a default context length of 4K, while its long context variant, phi-3-mini-128K, extends this to 128K using LongRope. Utilising the structure of Llama-2, it shares a similar block configuration and tokeniser with a vocabulary size of 320,641, enabling seamless adaptation of Llama-2 packages. With 3,072 hidden dimensions, 32 heads, and 32 layers, the model is trained on 3.3 trillion tokens using bfloat16. Optimised for mobile devices, the phi-3-mini can be quantised to 4 bits, occupying approximately 1.8GB of memory and achieving over 12 tokens per second on an iPhone 14 with the A16 Bionic chip.
The training methodology builds upon prior works, focusing on high-quality training data to enhance small language model performance. Unlike previous approaches, it emphasizes data quality over computational efficiency or overtraining, filtering web data to align with the model’s educational and reasoning goals. The model’s performance is compared to Llama-2 models, illustrating its efficacy near the “Data Optimal Regime.” Also, a larger model, phi-3-medium, with 14B parameters, is trained using similar methods but shows less improvement, suggesting ongoing refinement of the data mixture. Post-training involves supervised instruction fine-tuning and preference tuning with DPO, enhancing the model’s chat capabilities, robustness, and safety.
The researchers extended their investigation by training phi-3-medium, a model with 14B parameters, using the same tokenizer and architecture as phi-3-mini. Trained on the same data for slightly longer epochs (4.8T tokens in total, akin to phi-3-small), phi-3-medium features 40 heads, 40 layers, and an embedding dimension 5120. Interestingly, they noted that while certain benchmarks exhibited significant improvement from 3.8B to 7B parameters, the progress was less pronounced from 7B to 14B parameters. This observation suggests that further refinement of the data mixture is necessary to achieve the “data optimal regime” for the 14B parameters model. Ongoing investigation into these benchmarks, including regression on HumanEval, indicates that the reported metrics for phi-3-medium should be viewed as a preliminary assessment.
While the phi-3-mini achieves commendable language understanding and reasoning akin to larger models, its size limits its storage of extensive factual knowledge, leading to lower performance on tasks like TriviaQA. Augmentation with a search engine could address this. Also, its predominantly English focus highlights the need to explore multilingual capabilities, showing initial promise in phi-3-small with added multilingual data.
In conclusion, this research introduces the phi-3-mini model, which showcases the potential for smaller models to achieve comparable performance to larger counterparts but with inherent limitations. Further exploration into multilingual capabilities and augmentation with search engines could enhance the effectiveness of smaller LLMs in addressing diverse language tasks.
Check out the Paper and HF Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post Microsoft AI Releases Phi-3 Family of Models: A 3.8B Parameter Language Model Trained on 3.3T Tokens Locally on Your Phone appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]