


Object segmentation across images and videos is a complex yet pivotal task. Traditionally, this field has witnessed a siloed progression, with different tasks such as referring image segmentation (RIS), few-shot image segmentation (FSS), referring video object segmentation (RVOS), and video object segmentation (VOS) evolving independently. This disjointed development resulted in inefficiencies and an inability to leverage multi-task learning benefits effectively.
At the heart of object segmentation challenges lies precisely identifying and delineating objects. This becomes exponentially complex in dynamic video contexts or involves interpreting objects based on linguistic descriptions. For instance, RIS often requires the fusion of vision and language, demanding deep cross-modal integration. On the other hand, FSS emphasizes correlation-based methods for dense semantic correspondence. Video segmentation tasks have historically relied on space-time memory networks for pixel-level matching. This divergence in methodologies led to specialized, task-specific models that consumed considerable computational resources and needed a unified approach for multi-task learning.
Researchers from The University of Hong Kong, ByteDance, Dalian University of Technology, and Shanghai AI Laboratory introduced UniRef++, a revolutionary approach to bridging these gaps. UniRef++ is a unified architecture designed to seamlessly integrate four critical object segmentation tasks. Its innovation lies in the UniFusion module, a multiway-fusion mechanism that handles tasks based on their specific references. This module’s capability to fuse information from visual and linguistic references is especially crucial for tasks like RVOS, which require understanding language descriptions and tracking objects across videos.
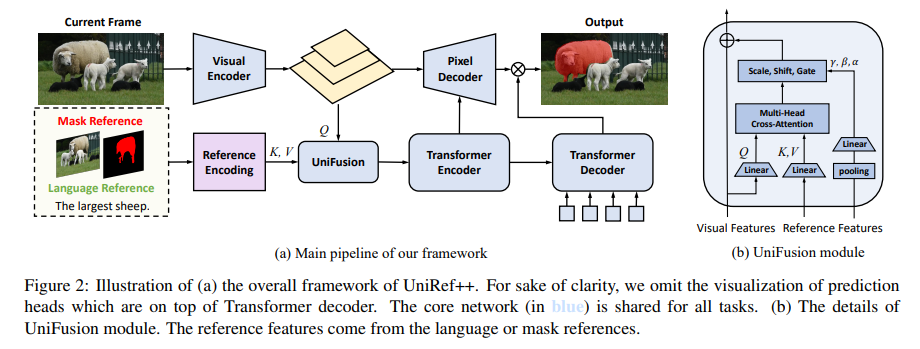
Unlike other benchmarks, UniRef++ may be collaboratively taught across a wide range of activities, allowing it to absorb broad information that can be used for a variety of jobs. This strategy works, as demonstrated by competitive outcomes in FSS and VOS and superior performance in RIS and RVOS tasks. UniRef++’s flexibility enables it to execute numerous functions at runtime with just the correct references specified. This provides a flexible approach that smoothly transitions between verbal and visual references.

The implementation of UniRef++ in the domain of object segmentation is not just an incremental improvement but a paradigm shift. Its unified architecture addresses the longstanding inefficiencies of task-specific models and lays the groundwork for more effective multi-task learning in image and video object segmentation. The model’s ability to amalgamate various tasks under a single framework, transitioning seamlessly between linguistic and visual references, is exemplary. It sets a new standard in the field, offering insights and directions for future research and development.
Check out the Paper and Code. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post Meet UniRef++: A Game-Changer AI Model in Object Segmentation with Unified Architecture and Enhanced Multi-Task Performance appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]