


Large Language Models (LLMs) have become increasingly pivotal in the burgeoning field of artificial intelligence, especially in data management. These models, which are based on advanced machine learning algorithms, have the potential to streamline and enhance data processing tasks significantly. However, integrating LLMs into repetitive data generation pipelines is challenging, mainly due to their unpredictable nature and the possibility of significant output errors.
Operationalizing LLMs for large-scale data generation tasks is fraught with complexities. For instance, in functions like generating personalized content based on user data, LLMs might perform highly in a few cases but also risk causing incorrect or inappropriate content. This inconsistency can lead to significant issues, particularly when LLM outputs are used in sensitive or critical applications.
Managing LLMs within data pipelines has relied heavily on manual interventions and basic validation methods. Developers face substantial challenges in predicting all potential failure modes of LLMs. This difficulty leads to an over-reliance on basic frameworks incorporating rudimentary assertions to filter out erroneous data. These assertions, while useful, need to be more comprehensive to catch all types of errors, leaving gaps in the data validation process.
The introduction of Spade, a method for synthesizing assertions in LLM pipelines by researchers from UC Berkeley, HKUST, LangChain, and Columbia University, significantly advances this area. Spade addresses the core challenges in LLM reliability and accuracy by innovatively synthesizing and filtering assertions, ensuring high-quality data generation in various applications. It functions by analyzing the differences between consecutive versions of LLM prompts, which often indicate specific failure modes of the LLMs. Based on this analysis, spade synthesizes Python functions as candidate assertions. These functions are then meticulously filtered to ensure minimal redundancy and maximum accuracy, addressing the complexities of LLM-generated data.
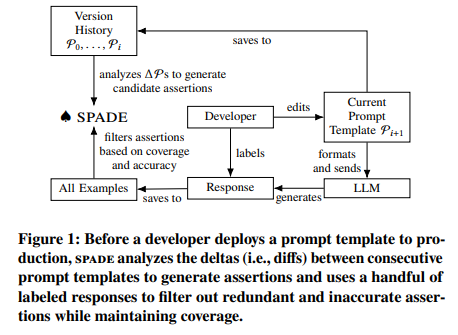
Spade’s methodology involves generating candidate assertions based on prompt deltas – the differences between consecutive prompt versions. These deltas often indicate specific failure modes that LLMs might encounter. For example, an adjustment in a prompt to avoid complex language might necessitate an assertion to check the response’s complexity. Once these candidate assertions are generated, they undergo a rigorous filtering process. This process aims to reduce redundancy, which often stems from repeated refinements to similar portions of a prompt, and to enhance accuracy, particularly in assertions involving complex LLM calls.
In practical applications, across various LLM pipelines, it has significantly reduced the number of necessary assertions and decreased the rate of false failures. This is evident in its ability to reduce the number of assertions by 14% and decrease false failures by 21% compared to simpler baseline methods. These results highlight Spade’s capability to enhance the reliability and accuracy of LLM outputs in data generation tasks, making it a valuable tool in data management.

In summary, the following points can presented on the research conducted:
- Spade represents a breakthrough in managing LLMs in data pipelines, addressing the unpredictability and error potential in LLM outputs.
- It generates and filters assertions based on prompt deltas, ensuring minimal redundancy and maximum accuracy.
- The tool has significantly reduced the number of necessary assertions and the rate of false failures in various LLM pipelines.
- Its introduction is a testament to the ongoing advancements in AI, particularly in enhancing the efficiency and reliability of data generation and processing tasks.
This comprehensive overview of Spade underscores its importance in the evolving landscape of AI and data management. Spade ensures high-quality data generation by addressing the fundamental challenges associated with LLMs. It simplifies the operational complexities associated with these models, paving the way for their more effective and widespread use.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post Meet Spade: An AI Method for Automatically Synthesizing Assertions that Identify Bad LLM Outputs appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]