


Advancements in large language models (LLMs) have been witnessed across various domains, such as translation, healthcare, and code generation. These models have shown exceptional capabilities in understanding and generating human-like text. Despite their success, the legal domain has yet to benefit fully from this technology. Legal professionals grapple with vast volumes of complex documents, highlighting the need for a dedicated LLM to navigate and interpret legal material effectively. This underscores the urgency for further development and implementation of LLMs tailored for legal applications.
The researchers from Equall.ai, MICS, CentraleSupélec, Université Paris-Saclay, Sorbonne Université, Instituto Superior Técnico, Universidade de Lisboa, NOVA School of Law introduce SaulLM-7B, the first publicly available legal LLM, uniquely designed for legal text. It leverages extensive pretraining on dedicated legal corpora from English-speaking jurisdictions like the USA, Canada, the UK, and Europe to enhance understanding of legal complexities. The model is designed to adapt to evolving legal discourse, empowering legal practitioners and driving innovation in artificial intelligence and the legal community.
The researchers adopt the backbone of the Mistral 7B model, a high-performing open-source LLM with 7 billion parameters. They enhance their legal capabilities through continued pretraining on a meticulously curated 30 billion token legal corpus. They improve legal instruction by fine-tuning it with generic and legal-specific instructions. This process results in SaulLM-7B-Instruct, adept at addressing legal queries and excelling in various legal tasks.
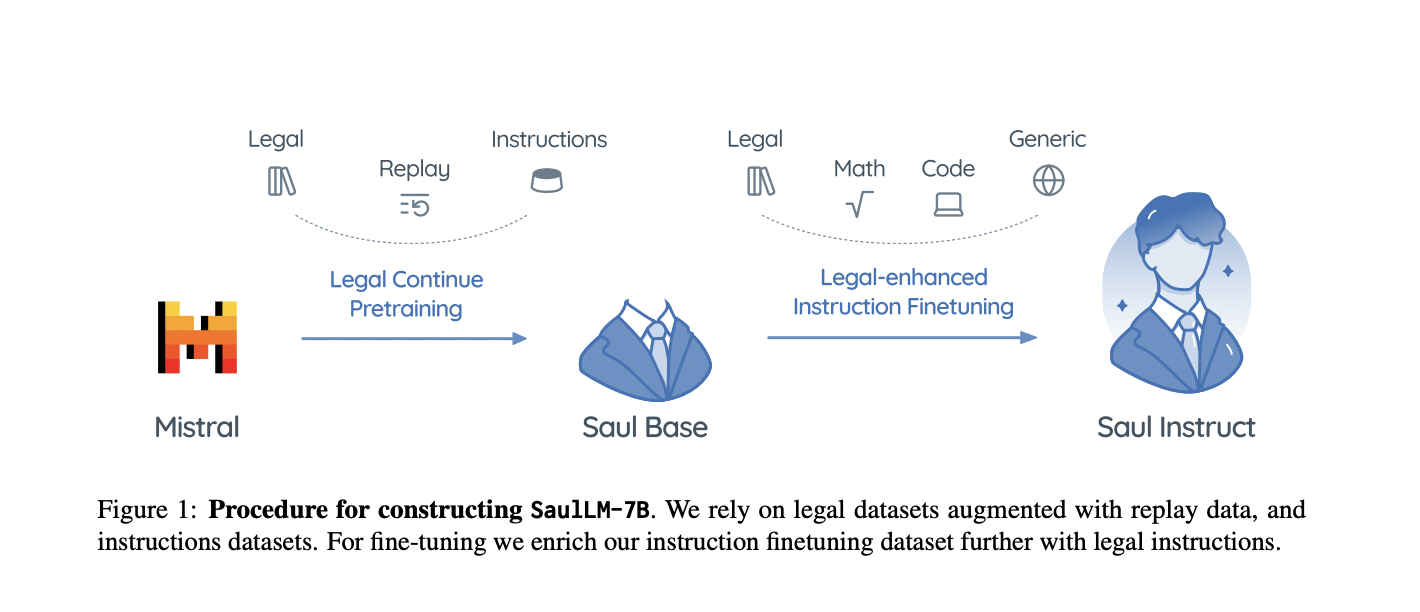
The researchers meticulously collected legal texts from various jurisdictions, primarily focusing on English-speaking countries like the U.S., Europe, and Australia. They combined previously available datasets with scraped data from publicly available sources, resulting in a comprehensive corpus of 30 billion tokens. To ensure data quality, they undertook aggressive cleaning and deduplication steps, filtering noise and removing duplicates. They also incorporated replay sources and conversational data to enhance the model’s performance during pretraining.
The experimental findings provide compelling evidence of SaulLM-7B-Instruct’s superior performance in understanding legal language and its application. It outperforms Mistral-Instruct and other non-legal models on LegalBench-Instruct and Legal-MMLU benchmarks, demonstrating its superiority in tasks requiring legal-specific knowledge. While SaulLM-7B-Instruct excels in legal expertise-related tasks, it presents opportunities for improvement in conclusion tasks that demand more deductive reasoning. It is a robust foundation for tailored legal workflows, underscoring its potential for further enhancement.
In conclusion, researchers from Equall.ai, MICS, CentraleSupélec, Université Paris-Saclay, Sorbonne Université, Instituto Superior Técnico, Universidade de Lisboa, NOVA School of Law present SaulLM-7B. This open-source decoder model achieves state-of-the-art performance in the legal domain among 7B models. Their approach involves fine-tuning legal data and instruction fine-tuning on synthetic datasets. They also offer a cleaned version of LegalBench and introduce a new set of documents for perplexity measurement, contributing significantly to the advancement of legal language processing.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
Want to get in front of 1.5 Million AI enthusiasts? Work with us here
The post Meet SaulLM-7B: A Pioneering Large Language Model for Law appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]