


In recent years, there has been remarkable progress in speech generation, achieving one-shot generation capability virtually indistinguishable from real human voice. The demand for lifelike speech synthesis is crucial for widespread adoption in modern AI applications, particularly in conversational systems like voice assistants.
The advent of deep learning architectures has significantly improved neural text-to-speech (TTS) synthesis. Conversational TTS, a cornerstone for lifelike user experiences, remains challenging due to the need for adaptability across various scenarios and domains. Most current TTS models are trained and evaluated in controlled environments, ignoring the conversational nature of real-world speech with its paralinguistic nuances, prosodic variations, and expressiveness.
Efficiency is a key practical consideration for TTS systems. It encompasses parameter efficiency, data efficiency, and inference efficiency. Compact models that can run on consumer hardware, learn effectively with limited data, and operate with low latency in real-life applications are essential. This work introduces PHEME, a Transformer-based TTS system developed by PolyAI, addressing the challenges of conversational synthesis and efficiency.
PHEME aims to provide high-quality TTS in multi-speaker and single-speaker scenarios, emphasizing natural prosody and adaptability. It focuses on compact, shareable models that can be fine-tuned easily, reducing pre-training time and data requirements and ensuring high inference efficiency.
The methodology behind PHEME involves three main components: speech tokenization, learning of the text-to-speech (T2S) component, and parallel non-autoregressive decoding for the acoustic-to-speech (A2S) component.
Speech Tokenization: PHEME employs the SpeechTokenizer model, unifying semantic and acoustic tokens. Unlike other methods, it aims to disentangle different aspects of speech information hierarchically across corresponding RVQ layers.
T2S: Training and Inference: The T2S component treats text-to-speech as a standard sequence-to-sequence problem, utilizing a T5-style encoder-decoder architecture. Ground truth semantic tokens are obtained through SpeechTokenizer. During inference, PHEME accepts speech prompts along with their text transcriptions, allowing for prompt-driven synthesis.
A2S: Training and Inference: The A2S component adopts a non-autoregressive procedure, extending the SoundStorm method. This design enables both one-shot and zero-shot speech generation, providing flexibility in prompts and speaker embeddings.
The experimental setup involves training PHEME in two sizes: SMALL (100M parameters) and LARGE (300M parameters). Evaluation metrics cover speech intelligibility, voice preservation, reconstruction error, prosody diversity, naturalness, and inference efficiency.
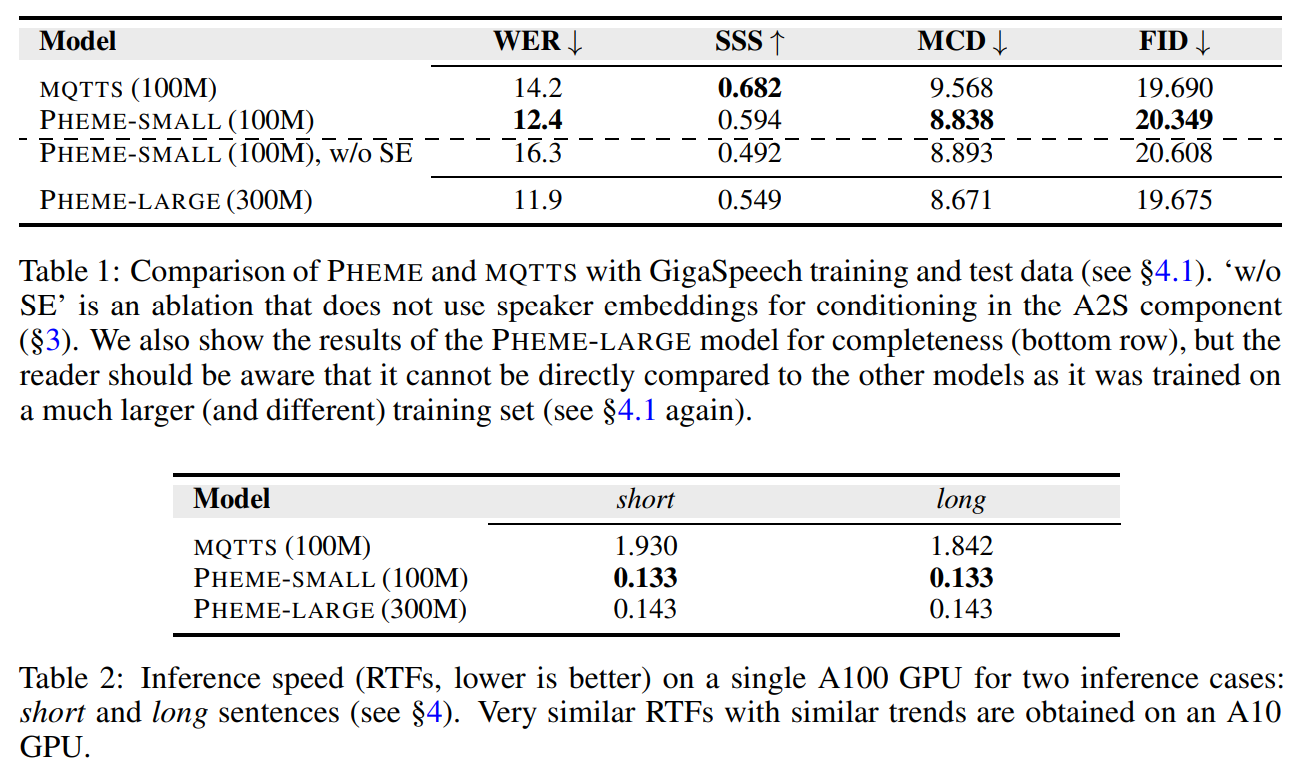
Comparative results (Table 1 and Table 2) with MQTTS reveal that PHEME, despite having faster non-autoregressive inference, outperforms MQTTS in terms of WER (Word Error Rate) and MCD(Mel-cepstral Distortion). PHEME maintains desirable qualities such as conversational nature, parameter efficiency, and sample efficiency while offering scalability and improved synthesis quality. The 300M PHEME variant demonstrates gains over the 100M variant.
Inference speed (RTF-Real-Time Factor) comparisons show significant efficiency benefits with PHEME, making it almost 15 times quicker than MQTTS without compromising generation quality.
In conclusion, PHEME TTS models aim to create high-quality, production-friendly, and efficient conversational systems. Systematizing recent advancements in Transformer-based TTS models, PHEME demonstrates the possibility of building highly efficient models with faster inference and improved speech generation quality. The models shared with the community serve as a foundation for further developments in conversational TTS systems, focusing on the interplay between synthesis quality and efficiency. Future research may explore other architectures, decoding strategies, parameter-efficient designs, multilingual TTS, or data collection for high-quality conversational TTS.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
The post Meet PHEME: PolyAI’s Advanced Transformer-Based TTS System for Efficient and Conversational Synthesis appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #Sound #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]