


The generation of hyper-realistic human images from user-defined conditions, such as text and pose, is meaningful for various applications, including image animation and virtual try-ons. Numerous efforts have been made to explore the task of controllable human image generation. Early methods either relied on variational auto-encoders (VAEs) in a reconstruction manner or improved realism through generative adversarial networks (GANs). Despite the creation of high-quality images by some methods, challenges like unstable training and limited model capacity confined them to small datasets with low diversity.
The recent emergence of diffusion models (DMs) has introduced a new paradigm for realistic synthesis, becoming the predominant architecture in Generative AI. However, exemplar text-to-image (T2I) models like Stable Diffusion and DALL·E 2 still struggle to create human images with coherent anatomy, such as arms, legs, and natural poses. The primary challenge lies in the non-rigid deformations of the human form, requiring structural information that is difficult to depict solely through text prompts.
Recent works, such as ControlNet and T2I-Adapter, have attempted to enable structural control for image generation by introducing a learnable branch to modulate pre-trained DMs, like Stable Diffusion, in a plug-and-play manner. However, these approaches suffer from feature discrepancies between the main and auxiliary branches, resulting in inconsistency between control signals (e.g., pose maps) and generated images. HumanSD proposes directly inputting the body skeleton into the diffusion U-Net through channel-wise concatenation to address this. However, this method is confined to generating artistic-style images with limited diversity. Additionally, human content is synthesized only with pose control, neglecting other crucial structural information like depth maps and surface-normal maps.
The work reported in this article proposes a unified framework, HyperHuman, to generate in-the-wild human images with high realism and diverse layouts. Its overview is illustrated in the figure below.
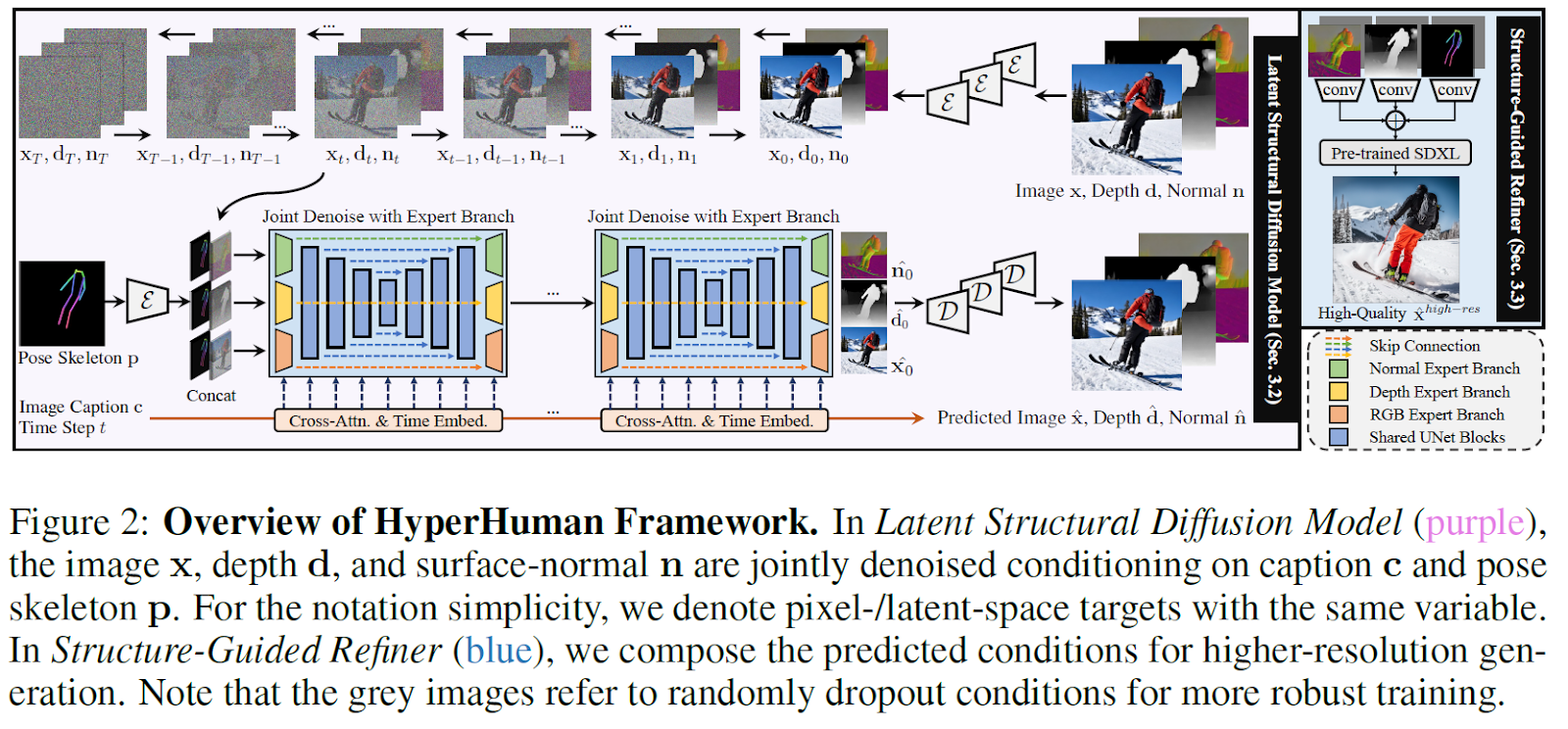
The key insight is recognizing the inherently structural nature of human images across multiple granularities, from coarse-level body skeletons to fine-grained spatial geometry. Capturing such correlations between explicit appearance and latent structure in one model is essential for generating coherent and natural human images. The paper establishes a large-scale human-centric dataset called HumanVerse, containing 340 million in-the-wild human images with comprehensive annotations. Based on this dataset, two modules are designed for hyper-realistic controllable human image generation: the Latent Structural Diffusion Model and the Structure-Guided Refiner. The former augments the pre-trained diffusion backbone to simultaneously denoise RGB, depth, and normal aspects, ensuring spatial alignment among denoised textures and structures.
Due to such meticulous design, the modeling of image appearance, spatial relationships, and geometry occurs collaboratively within a unified network. Each branch complements the others, incorporating both structural awareness and textural richness. An enhanced noise schedule eliminates low-frequency information leakage, ensuring uniform depth and surface-normal values in local regions. Employing the same timestep for each branch enhances learning and facilitates feature fusion. With spatially-aligned structure maps, the Structure-Guided Refiner composes predicted conditions for detailed, high-resolution image generation. Additionally, a robust conditioning scheme is designed to alleviate the impact of error accumulation in the two-stage generation pipeline.
A comparison with state-of-the-art techniques is reported below.

The first 4×4 grid of each row contains the input skeleton, jointly denoised normal, depth, and coarse RGB (512×512) as computed by HyperHuman.
This was the summary of HyperHuman, a novel AI framework for generating in-the-wild human images with high realism and diverse layouts. If you are interested and want to learn more about it, please feel free to refer to the links cited below.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post Meet HyperHuman: A Novel AI Framework for Hyper-Realistic Human Generation with Latent Structural Diffusion appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]