


The evolution of Vision Language Models (VLMs) towards general-purpose models relies on their ability to understand images and perform tasks via natural language instructions. However, it must be clarified if current VLMs truly grasp detailed object information in images. The analysis shows that their image understanding correlates strongly with zero-shot performance on vision language tasks. It suggests that prioritizing basic image understanding is key for VLMs to excel. Despite recent advancements, leading VLMs still struggle with fine-grained object comprehension, impacting their performance on related tasks. Improving VLMs’ object-level understanding is essential for enhancing their overall task performance.
Researchers from KAIST have developed CoLLaVO, a model merging language and vision capabilities to improve object-level image understanding. By introducing the Crayon Prompt, which utilizes panoptic color maps to guide attention to objects, and employing Dual QLoRA to balance learning from crayon instructions and visual prompts, CoLLaVO achieves substantial advancements in zero-shot vision language tasks. This innovative approach maintains object-level understanding while enhancing complex task performance. CoLLaVO-7B demonstrates superior zero-shot performance compared to existing models, marking a significant stride in effectively bridging language and vision domains.
In the realm of language and vision models, research has concentrated on refining natural language prompts for LLMs and exploring new avenues for VLMs. Previous studies have experimented with various visual prompting techniques to optimize prompts for improved model performance. However, the interpretability of learned visual prompts has remained a challenge. Current VLMs employ human-interpretable visual prompts such as marks or semantic masks to enhance model understanding. Visual prompts such as learnable token embedding, learned perturbation patterns, marks, and semantic masks have guided VLMs toward specific image areas.
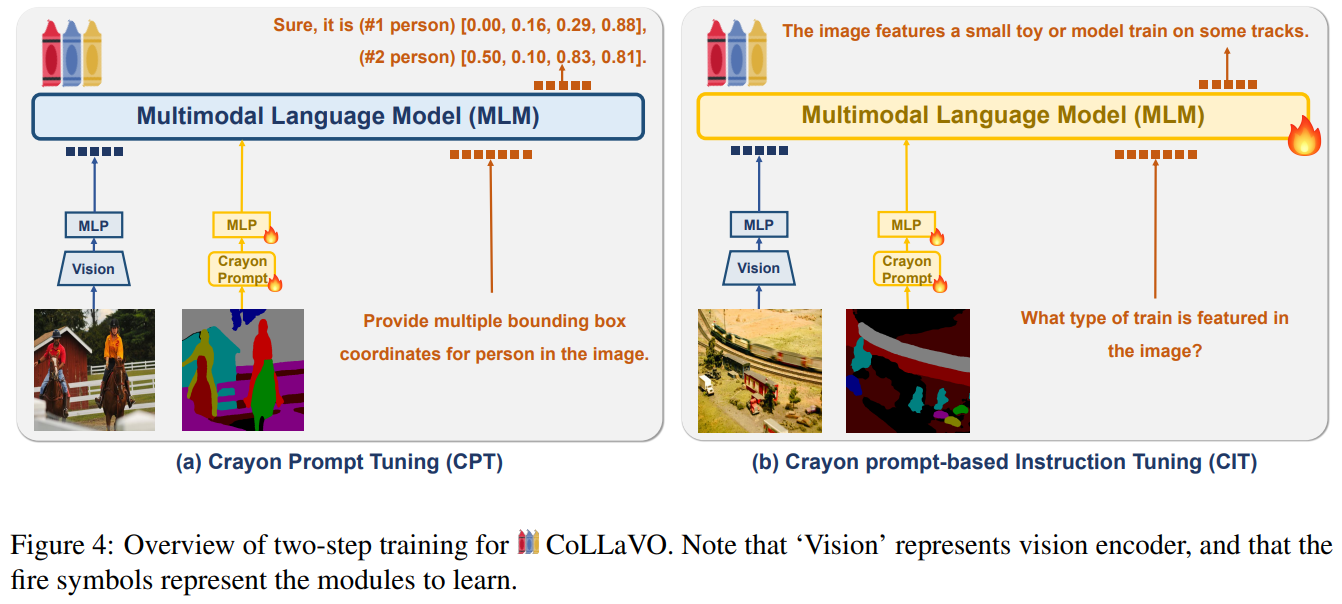
CoLLaVO’s architecture integrates a vision encoder, Crayon Prompt, backbone MLM, and MLP connectors. The vision encoder, CLIP, aids in image understanding, while the MLM, InternLM-7B, supports multilingual instruction tuning. The Crayon Prompt, generated from a panoptic color map, incorporates semantic and numbering queries to represent objects in the image. Crayon Prompt Tuning (CPT) aligns this prompt with the MLM to enhance object-level understanding. Crayon Prompt-based Instruction Tuning (CIT) leverages visual instruction tuning datasets and crayon instructions for complex VL tasks. Dual QLoRA manages object-level understanding and VL performance during training to maintain both capabilities effectively.
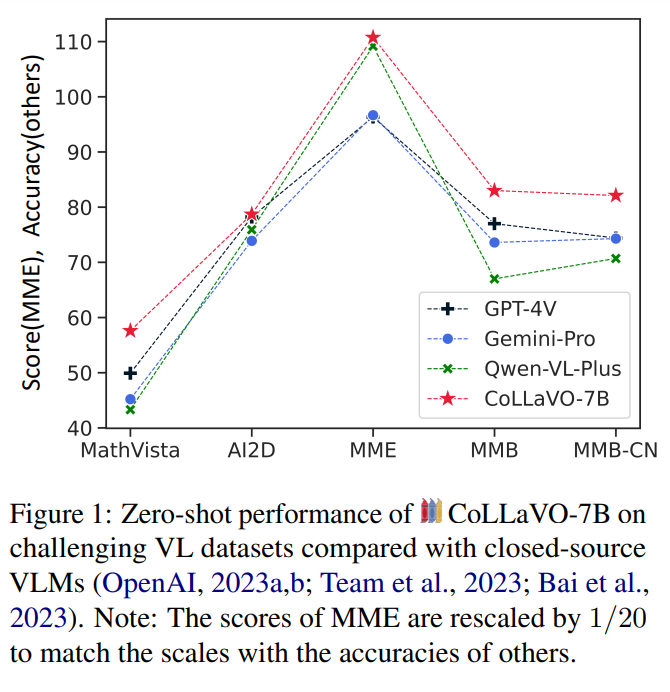
The image understanding capabilities of current VLMs were found to be strongly correlated with their zero-shot performance on vision language tasks. It suggests that prioritizing basic image understanding is crucial for VLMs to excel at vision language tasks. The CoLLaVO incorporates instruction tuning with Crayon Prompt, a visual prompt tuning scheme based on panoptic color maps. CoLLaVO achieved a significant leap in numerous vision language benchmarks in a zero-shot setting, demonstrating enhanced object-level image understanding. The study mentions commendable scores achieved across all zero-shot tasks, indicating the model’s effectiveness.
In conclusion, CoLLaVO demonstrates exceptional performance across various vision language tasks, thanks to its innovative features like the Crayon Prompt and Dual QLoRA. CoLLaVO achieves state-of-the-art results with a relatively compact model size by effectively integrating object-level image understanding. It surpasses closed-source and open-source VLMs in reducing hallucination, indicating its superior grasp of image context. These findings highlight the significance of prioritizing object-level understanding in VLM design, proving its effectiveness even amidst the trend of scaling up models and creating custom instruction tuning datasets.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Meet CoLLaVO: KAIST’s AI Breakthrough in Vision Language Models Enhancing Object-Level Image Understanding appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]