


Artificial intelligence has witnessed a remarkable shift towards integrating multimodality in large language models (LLMs), a development poised to revolutionize how machines understand and interact with the world. This shift is driven by the understanding that the human experience is inherently multimodal, encompassing not just text but also speech, images, and music. Thus, enhancing LLMs with the ability to process and generate multiple modalities of data could significantly improve their utility and applicability in real-world scenarios.
One of the pressing challenges in this burgeoning field is creating a model capable of seamlessly integrating and processing multiple modalities of data. Traditional methods have made strides by focusing on dual-modality models, primarily combining text with one other form of data, such as images or audio. However, these models often need to catch up when handling more complex, multimodal interactions involving more than two data types simultaneously.
Addressing this gap, researchers from Fudan University, alongside collaborators from the Multimodal Art Projection Research Community and Shanghai AI Laboratory, have introduced AnyGPT. This innovative LLM distinguishes itself by utilizing discrete representations for processing a wide array of modalities, including text, speech, images, and music. Unlike its predecessors, AnyGPT can train without significantly modifying the existing LLM architecture. This stability is achieved through data-level preprocessing, which simplifies the integration of new modalities into the model.
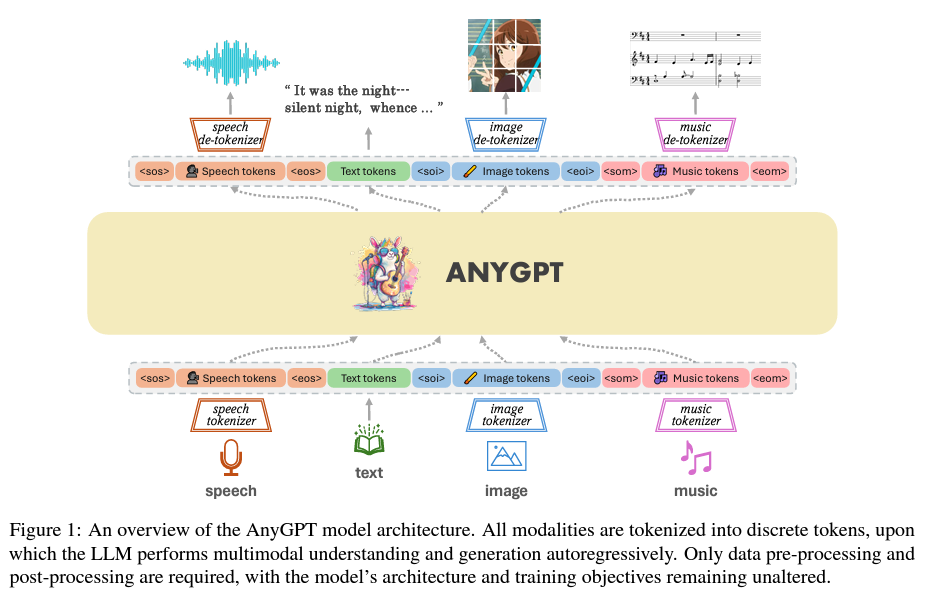
The methodology behind AnyGPT is both intricate and groundbreaking. The model compresses raw data from various modalities into a unified sequence of discrete tokens by employing multimodal tokenizers. This allows AnyGPT to perform multimodal understanding and generation tasks, leveraging the robust text-processing capabilities of LLMs while extending them across different data types. The model’s architecture facilitates the autoregressive processing of these tokens, enabling it to generate coherent responses that incorporate multiple modalities.
AnyGPT’s performance is a testament to its revolutionary design. The model demonstrated capabilities on par with specialized models across all tested modalities in evaluations. For instance, in image captioning tasks, AnyGPT achieved a CIDEr score of 107.5, showcasing its ability to understand and describe pictures accurately. The model attained a score of 0.65 in text-to-image generation, illustrating its proficiency in creating relevant visual content from textual descriptions. Moreover, AnyGPT showcased its strength in speech with a Word Error Rate (WER) of 8.5 on the LibriSpeech dataset, highlighting its effective speech recognition capabilities.
The implications of AnyGPT’s performance are profound. By demonstrating the feasibility of any-to-any multimodal conversation, AnyGPT opens new avenues for developing AI systems capable of engaging in more nuanced and complex interactions. The model’s success in integrating discrete representations for multiple modalities within a single framework underscores the potential for LLMs to transcend traditional limitations, offering a glimpse into a future where AI can seamlessly navigate the multimodal nature of human communication.
In conclusion, the development of AnyGPT by the research team from Fudan University and its collaborators marks a significant milestone in artificial intelligence. By bridging the gap between different modalities of data, AnyGPT not only enhances the capabilities of LLMs but also paves the way for more sophisticated and versatile AI applications. The model’s ability to process and generate multimodal data could revolutionize various domains, from digital assistants to content creation, making AI interactions more relatable and effective. As the research community continues to explore and expand the boundaries of multimodal AI, AnyGPT stands as a beacon of innovation, highlighting the untapped potential of integrating diverse data types within a unified model.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Meet AnyGPT: Bridging Modalities in AI with a Unified Multimodal Language Model appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]