


The field of research focuses on enhancing large multimodal models (LMMs) to process and understand extremely long video sequences. Video sequences offer valuable temporal information, but current LMMs need help to understand exceptionally long videos. This issue stems from the sheer volume of visual tokens generated by the vision encoders, making it challenging for existing models to handle them efficiently.
One significant problem this research addresses is the need for current LMMs to effectively process and understand long videos. This challenge arises due to the excessive number of visual tokens produced by vision encoders. For instance, models like LLaVA-1.6 generate between 576 and 2880 visual tokens for a single image, which escalates significantly with more frames. This creates a bottleneck in processing and understanding long video sequences, necessitating innovative solutions.
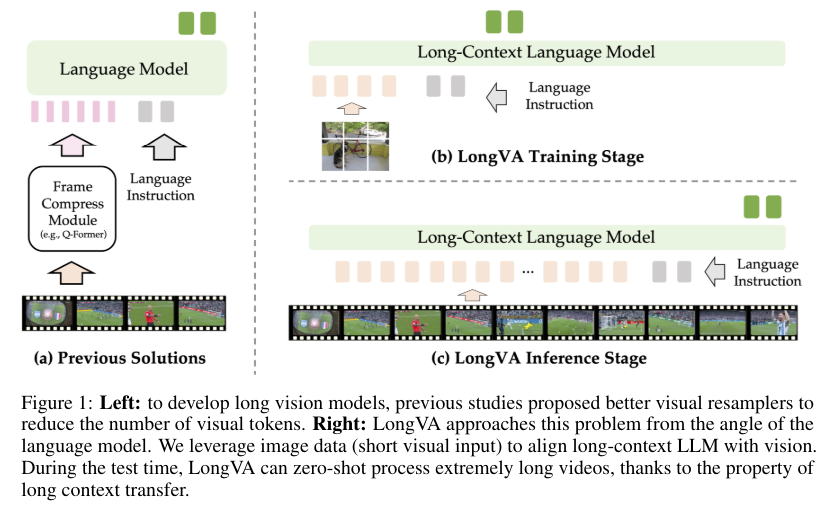
Existing methods to tackle this problem include visual resamplers to reduce the number of visual tokens and heuristic techniques to prune or merge visual features. Despite these efforts, most LMMs still need help to process many frames effectively. Current methods like the visual resampler used by models such as MPLUG-Owl-video and MovieChat attempt to compress the visual features but must catch up when dealing with extensive video data.
Researchers from the LMMs-Lab Team, NTU, and SUTD in Singapore have introduced an innovative approach called Long Context Transfer to address this challenge. This approach extends the context length of the language model backbone, enabling it to process a significantly larger number of visual tokens. This method is unique because it does not require additional video training. Instead, it leverages the extended context length of the language model, allowing LMMs to comprehend orders of magnitude more visual tokens. This research was conducted by the LMMs-Lab team.
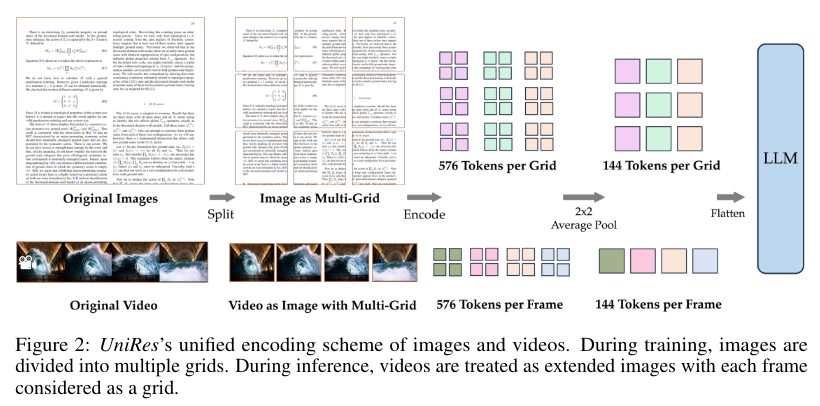
The proposed model, Long Video Assistant (LongVA), extends the context length of the language model by training it on longer text data. This context-extended language model is then aligned with visual inputs, allowing the model to process long videos effectively without additional complexity. The UniRes encoding scheme, which unifies the representation of images and videos, plays a crucial role in this process. LongVA can treat videos as extended images during inference, significantly enhancing its ability to process long video sequences.
LongVA’s performance on the Video-MME dataset demonstrates its capability to handle long videos. It can process up to 2000 frames or over 200,000 visual tokens, setting a new benchmark in this area. The Visual Needle-In-A-Haystack (V-NIAH) benchmark was developed to measure LMMs’ ability to locate and retrieve visual information over long contexts. LongVA showed superior performance in these evaluations, retrieving visual information accurately from up to 3000 frames.
Experiments showed that LongVA could effectively process and understand long videos, achieving state-of-the-art performance among 7B-scale models. The model was trained on a context length of 224K tokens, equivalent to 1555 frames, and it generalizes well beyond that, maintaining performance within 3000 frames. This demonstrates the effectiveness of the long context transfer phenomenon, where the extended context of the language model enhances the visual processing capabilities of the LMMs.
The researchers conducted detailed experiments to validate their approach. They used Qwen2-7B-Instruct as the backbone language model and performed continued pretraining with a context length of 224K over 900 million tokens. The training framework was designed to be memory efficient and maintain high GPU occupancy. The long context training was completed in just two days using eight A100 GPUs, showcasing the feasibility of this approach within academic budgets.

In conclusion, this research addresses the critical problem of processing and understanding long video sequences in large multimodal models. By extending the context length of the language model and aligning it with visual inputs, the researchers significantly improved the LMMs’ capability to handle long videos. The proposed LongVA model demonstrates substantial performance improvements, processing up to 2000 frames or over 200,000 visual tokens and setting a new standard for LMMs in this field. This work highlights the potential of long context transfer to enhance the capabilities of LMMs for long video processing.
Check out the Paper, Project, and Demo. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
 Create, edit, and augment tabular data with the first compound AI system, Gretel Navigator, now generally available! [Advertisement]
Create, edit, and augment tabular data with the first compound AI system, Gretel Navigator, now generally available! [Advertisement]
The post LongVA and the Impact of Long Context Transfer in Visual Processing: Enhancing Large Multimodal Models for Long Video Sequences appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]