


Large language models (LLMs) have revolutionized natural language processing (NLP) by achieving remarkable performance across tasks such as text generation, translation, sentiment analysis, and question-answering. Efficient fine-tuning is crucial for adapting LLMs to various downstream functions. It allows practitioners to utilize the model’s pre-trained knowledge while requiring less labeled data and computational resources than training from scratch. However, implementing these methods on different models requires non-trivial efforts.
Fine-tuning many parameters with limited resources becomes the main challenge of adapting LLM to downstream tasks. A popular solution is efficient fine-tuning, which reduces the training cost of LLMs when adapting to various tasks. Various other attempts have been made to develop methods for efficient fine-tuning LLM. Still, they need a systematic framework that adapts and unifies these methods to different LLMs and provides a friendly interface for user customization.
The researchers from the School of Computer Science and Engineering, Beihang University, and the School of Software and Microelectronics, Peking University, present LLAMAFACTORY. This framework democratizes the fine-tuning of LLMs. It unifies various efficient fine-tuning methods through scalable modules, enabling the fine-tuning hundreds of LLMs with minimal resources and high throughput. Also, it streamlines commonly used training approaches, including generative pre-training, supervised fine-tuning (SFT), reinforcement learning from human feedback (RLHF), and direct preference optimization (DPO). Users can utilize command-line or web interfaces to customize and fine-tune their LLMs with minimal or no coding effort.
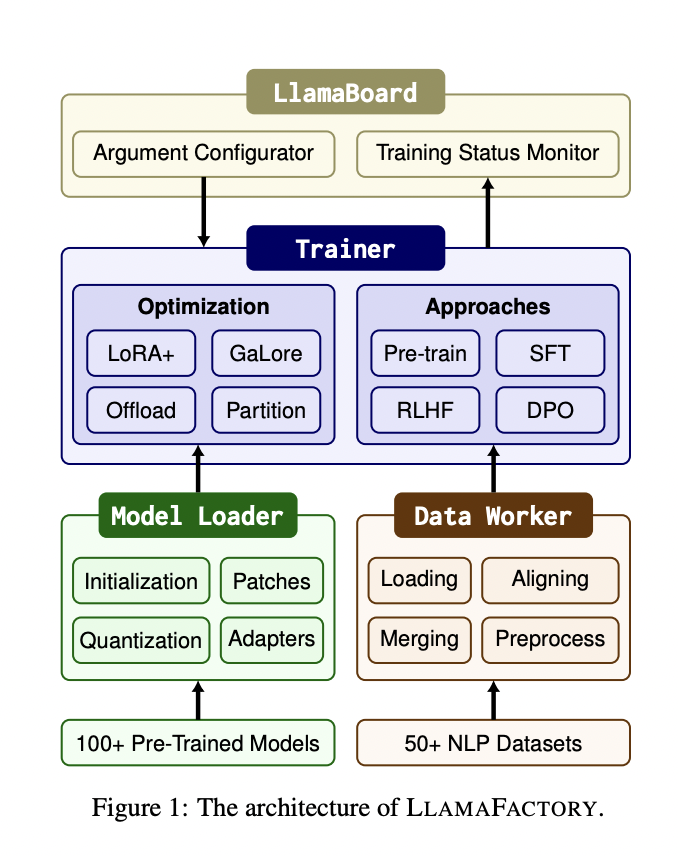
LLAMAFACTORY consists of three main modules: Model Loader, Data Worker, and Trainer. They used LLAMABOARD, which provides a friendly visual interface for the above modules. This enables users to configure and launch individual LLM fine-tuning processes codeless and monitor the training status on the fly.
- Model Loader: The model loader consists of four components: Model Initialization, Model Patching, Model Quantization, and Adapter Attaching. It prepares various architectures for fine-tuning and supports over 100 LLMs.
- Data Worker: The Data Worker processes data from different tasks through a well-designed pipeline supporting over 50 datasets.
- Trainer: The Trainer unifies efficient fine-tuning methods to adapt these models to different tasks and datasets, which offers four training approaches.
QLoRA consistently has the lowest memory footprint in training efficiency because the pre-trained weights are represented in lower precision. LoRA exhibits higher throughput by optimization in LoRA layers by Unsloth. GaLore achieves lower PPL on large models, while LoRA has advantages on smaller ones. In the evaluation results on downstream tasks, the averaged scores over ROUGE-1, ROUGE-2, and ROUGE-L for each LLM and each dataset were reported. LoRA and QLoRA perform best in most cases, except for the Llama2-7B and ChatGLM3- 6B models on the CNN/DM and AdGen datasets. Also, the Mistral-7B model performs better on English datasets, while the Qwen1.5-7B model achieves higher scores on the Chinese dataset.
In conclusion, the researchers have proposed LLAMAFACTORY, a unified framework for the efficient fine-tuning of LLMs. A modular design minimizes dependencies between the models, datasets, and training methods. It provided an integrated approach to fine-tuning over 100 LLMs with a diverse range of efficient fine-tuning techniques. Also, a flexible web UI LLAMABOARD was offered, enabling customized fine-tuning and evaluation of LLMs without coding efforts. They also empirically validate the efficiency and effectiveness of their framework on language modeling and text generation tasks.
Demo
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post LlamaFactory: A Unified Machine Learning Framework that Integrates a Suite of Cutting-Edge Efficient Training Methods, Allowing Users to Customize the Fine-Tuning of 100+ LLMs Flexibly appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]