


Multimodal learning is a rapidly evolving field focusing on training models to understand and generate content across various modalities, including text and images. By leveraging extensive datasets, these models can align visual and textual representations within a shared embedding space, facilitating applications such as image captioning and text-to-image retrieval. This integrated approach aims to enhance the model’s capability to handle diverse types of data inputs more efficiently.
The primary challenge addressed in this research is the inefficiency of current models in managing text-only and text-image tasks. Typically, existing models excel in one domain while underperforming in the other, necessitating separate systems for different types of information retrieval. This separation increases such systems’ complexity and resource demands, highlighting the need for a more unified approach.
Current methods like Contrastive Language-Image Pre-training (CLIP) align images and text through pairs of images and their captions. However, these models often struggle with text-only tasks because they cannot process longer textual inputs. This shortcoming leads to suboptimal performance in textual information retrieval scenarios, making it difficult to handle tasks requiring efficient understanding of larger bodies of text.
Jina AI Researchers introduced the Jina-clip-v1 model to solve these challenges. This open-sourced model employs a novel multi-task contrastive training approach designed to optimize the alignment of text-image and text-text representations within a single model. This method aims to unify the capabilities of handling both types of tasks effectively, reducing the need for separate models.
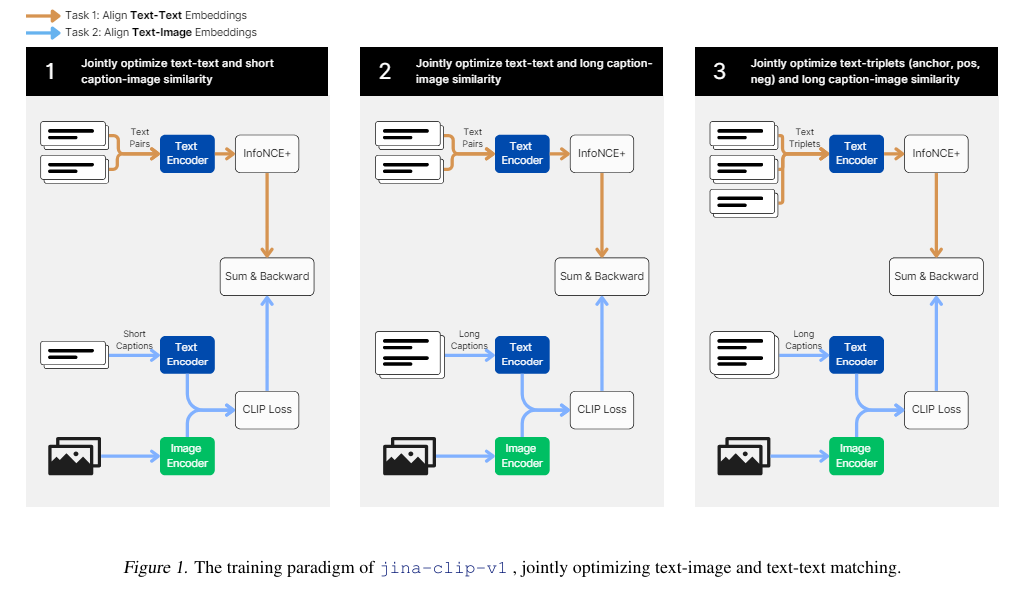
The proposed training method for jina-clip-v1 involves a three-stage process. The first stage focuses on aligning image and text representations using short, human-made captions, allowing the model to build a foundation in multimodal tasks. In the second stage, the researchers introduced longer, synthetic image captions to improve the model’s performance in text-text retrieval tasks. The final stage employs hard negatives to fine-tune the text encoder, enhancing its ability to distinguish relevant from irrelevant texts while maintaining text-image alignment.
Performance evaluations demonstrate that jina-clip-v1 achieves superior results in text-image and retrieval tasks. For instance, the model achieved an average Recall@5 of 85.8% across all retrieval benchmarks, outperforming OpenAI’s CLIP model and performing on par with EVA-CLIP. Additionally, in the Massive Text Embedding Benchmark (MTEB), which includes eight tasks involving 58 datasets, Jina-clip-v1 competes closely with top-tier text-only embedding models, achieving an average score of 60.12%. This performance is an improvement over other CLIP models by approximately 15% overall and 22% in retrieval tasks.
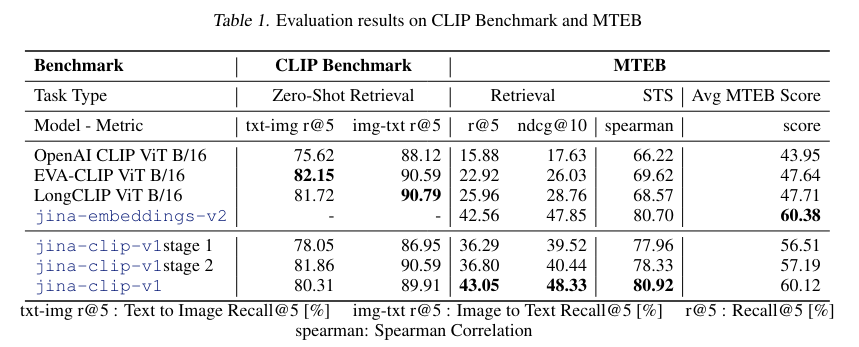
The detailed evaluation involved several training stages. For text-image training in Stage 1, the model used the LAION-400M dataset, which contains 400 million image-text pairs. This stage saw significant improvements in multimodal performance, though text-text performance initially fell short due to discrepancies in text lengths between training data types. Subsequent stages involved adding synthetic data with longer captions and using hard negatives, improving text-text and text-image retrieval performances.
The conclusion drawn from this research highlights the potential of unified multimodal models like Jina-clip-v1 to simplify information retrieval systems by combining text and image understanding capabilities within a single framework. This approach offers significant efficiency improvements for diverse applications by reducing the need for separate models for different task modalities, leading to potential savings in computational resources and complexity.

At last, the research introduces an innovative model that addresses the inefficiencies of current multimodal models by employing a multi-task contrastive training approach. The jina-clip-v1 model excels in text-image and retrieval tasks, demonstrating its ability to handle diverse data inputs effectively. This unified approach signifies a substantial advancement in multimodal learning, promising enhanced efficiency and performance for various applications.
Check out the Paper and Model. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post Jina AI Open Sources Jina CLIP: A State-of-the-Art English Multimodal (Text-Image) Embedding Model appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]