


Multimodal large language models (MLLMs) integrate text and visual data processing to enhance how artificial intelligence understands and interacts with the world. This area of research focuses on creating systems that can comprehend and respond to a combination of visual cues and linguistic information, mimicking human-like interactions more closely.
The challenge often lies in the limited capabilities of open-source models compared to their commercial counterparts. Open-source models frequently exhibit deficiencies in processing complex visual inputs and supporting various languages, which can restrict their practical applications and effectiveness in diverse scenarios.
Historically, most open-source MLLMs have been trained at fixed resolutions, primarily using datasets limited to the English language. This approach significantly hinders their functionality when encountering high-resolution images or content in other languages, making it difficult for these models to perform well in tasks that require detailed visual understanding or multilingual capabilities.
The research from Shanghai AI Laboratory, SenseTime Research, Tsinghua University, Nanjing University, Fudan University, and The Chinese University of Hong Kong introduces InternVL 1.5, an open-source MLLM designed to significantly enhance the capabilities of open-source systems in multimodal understanding. This model incorporates three major improvements to close the performance gap between open-source and proprietary commercial models. The three main components are:
- Firstly, a strong vision encoder, InternViT-6B, has been optimized through a continuous learning strategy, enhancing its visual understanding capabilities.
- Secondly, a dynamic high-resolution approach allows the model to handle images up to 4K resolution by dynamically adjusting image tiles based on the input’s aspect ratio and resolution.
- Lastly, a high-quality bilingual dataset has been meticulously assembled, covering common scenes and document images annotated with English and Chinese question-answer pairs.
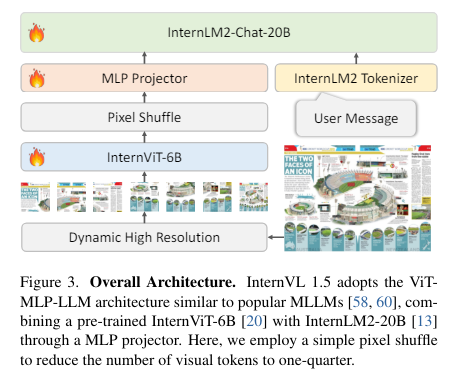
The three steps significantly boost the model’s performance in OCR and Chinese language-related tasks. These enhancements enable InternVL 1.5 to compete robustly in various benchmarks and comparative studies, showcasing its improved effectiveness in multimodal tasks. InternVL 1.5 employs a segmented approach to image handling, allowing it to process images in resolutions up to 4K by dividing them into tiles ranging from 448×448 pixels, adapting dynamically based on the image’s aspect ratio and resolution. This method improves image comprehension and facilitates understanding of detailed scenes and documents. The model’s enhanced linguistic capabilities stem from its training on a diverse dataset comprising both English and Chinese, covering a variety of scenes and document types, which boosts its performance in OCR and text-based tasks across languages.

The model’s performance is evidenced by its results across multiple benchmarks, where it excels particularly in OCR-related datasets and bilingual scene understanding. InternVL 1.5 demonstrates state-of-the-art results, showing marked improvements over previous versions and surpassing some proprietary models in specific tests. For example, text-based visual question answering achieves an accuracy of 80.6%, and document-based question answering reaches an impressive 90.9%. In multimodal benchmarks that assess models on both visual and textual understanding, InternVL 1.5 consistently delivers competitive results, often outperforming other open-source models and rivaling commercial models.

In conclusion, InternVL 1.5 addresses the significant challenges that open-source multimodal large language models face, particularly in processing high-resolution images and supporting multilingual capabilities. This model significantly narrows the performance gap with commercial counterparts by implementing a robust vision encoder, dynamic resolution adaptation, and a comprehensive bilingual dataset. The enhanced capabilities of InternVL 1.5 are demonstrated through its superior performance in OCR-related tasks and bilingual scene understanding, establishing it as a formidable competitor in advanced artificial intelligence systems.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post InternVL 1.5 Advances Multimodal AI with High-Resolution and Bilingual Capabilities in Open-Source Models appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]