


Authorship Verification (AV) is critical in natural language processing (NLP), determining whether two texts share the same authorship. This task holds immense importance across various domains, such as forensics, literature, and digital security. The traditional approach to AV relied heavily on stylometric analysis, which uses linguistic and stylistic features like word and sentence lengths and function word frequencies to differentiate between authors. With deep learning models like BERT and RoBERTa, the field has seen a paradigm shift. These modern approaches leverage complex patterns in text, offering superior performance compared to conventional stylometric techniques.
The primary challenge in Authorship Verification is to determine authorship accurately and provide clear and reliable explanations for the classification decisions. Current AV models focus mainly on binary classification, which often lacks transparency. This lack of explainability is a gap in academic interest and a practical concern. Analyzing the decision-making process of AI models is essential for building trust and reliability, particularly in identifying and addressing hidden biases. Therefore, AV models must be accurate and interpretable, providing detailed insights into their decision-making processes.
Existing methods for AV have advanced significantly with the use of deep learning models. BERT and RoBERTa, for example, have shown superior performance over traditional stylometric techniques. However, these models often need to provide clear explanations for their classifications. This is a critical limitation as the demand for explainable AI grows. Recent advancements have explored integrating explainability into these models, but challenges remain in ensuring that the explanations are consistent and relevant across various scenarios.
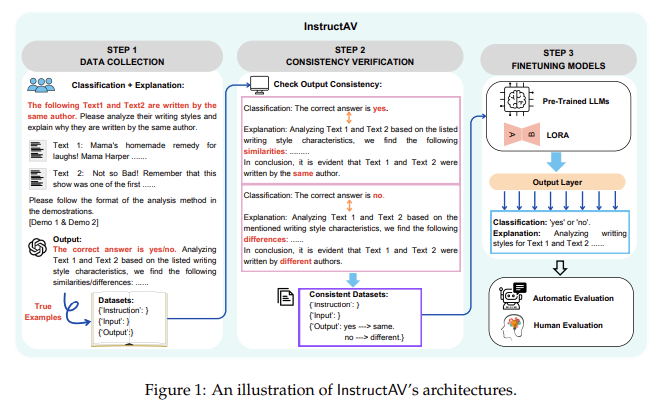
The Information Systems Technology and Design research team from the Singapore University of Technology and Design introduced a novel approach called InstructAV, which aims to enhance accuracy and explainability in authorship verification tasks. InstructAV utilizes large language models (LLMs) with a parameter-efficient fine-tuning (PEFT) method. This innovative framework is designed to align classification decisions with transparent and understandable explanations, marking a significant progression in the field. The InstructAV framework integrates explainability directly into the classification process, ensuring that the models make accurate predictions and provide deep insights into their decision-making logic. This dual capability is essential for advancing explainable artificial intelligence.
The methodology behind InstructAV involves three primary steps: data collection, consistency verification, and fine-tuning with the Low-Rank Adaptation (LoRA) method. Initially, the framework focuses on aggregating explanatory data for AV samples. This approach uses the binary classification labels available in existing AV datasets. Following this, a strict quality check is implemented to verify the alignment and consistency of the explanations with the corresponding classification labels. The final stage involves synthesizing instruction-tuning data, which combines the gathered classification labels and their associated explanations. This composite data is the foundation for fine-tuning LLMs using the LoRA adaptation technique. It ensures that the models are accurately fine-tuned for AV tasks while enhancing their capacity to provide coherent and reliable explanations.
The performance of InstructAV was evaluated through comprehensive experiments across diverse AV datasets, including IMDB, Twitter, and Yelp Reviews. The framework demonstrated state-of-the-art accuracy in authorship verification, significantly outperforming baseline models. For example, InstructAV with LLaMA-2-7B achieved an accuracy of 91.4% on the IMDB dataset, a substantial improvement over the highest-performing baseline, BERT, which gained 67.7%. InstructAV achieved high classification accuracy and set new benchmarks in generating coherent and substantiated explanations for its findings. The ROUGE-1 and ROUGE-2 scores highlighted InstructAV’s superior performance in achieving content overlap at both word and phrase levels. The BERT Score indicated that the explanations generated by InstructAV were semantically closer to the explanation labels, underscoring the framework’s capability to produce linguistically coherent and contextually relevant explanations.

In conclusion, the InstructAV framework addresses critical challenges in AV tasks by combining high classification accuracy with the ability to generate detailed and reliable explanations. The dual focus on performance and interpretability positions InstructAV as a state-of-the-art solution in the domain. The research team has made several key contributions, including developing the InstructAV framework, creating three instruction-tuning datasets with reliable linguistic explanations, and demonstrating the framework’s effectiveness through both automated and human evaluations. InstructAV’s ability to enhance classification accuracy while providing high-quality explanations marks crucial progress in AV research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Find Upcoming AI Webinars here
The post InstructAV: Transforming Authorship Verification with Enhanced Accuracy and Explainability Through Advanced Fine-Tuning Techniques appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #Technology [Source: AI Techpark]