


Scaling up LLMs presents significant challenges due to the immense computational resources needed and the need for high-quality datasets. Typically, the pre-training process involves utilizing models with billions of parameters and training them on datasets containing trillions of tokens. This intricate procedure demands substantial computational power and access to high-quality data to achieve better performance in language understanding and generation tasks.
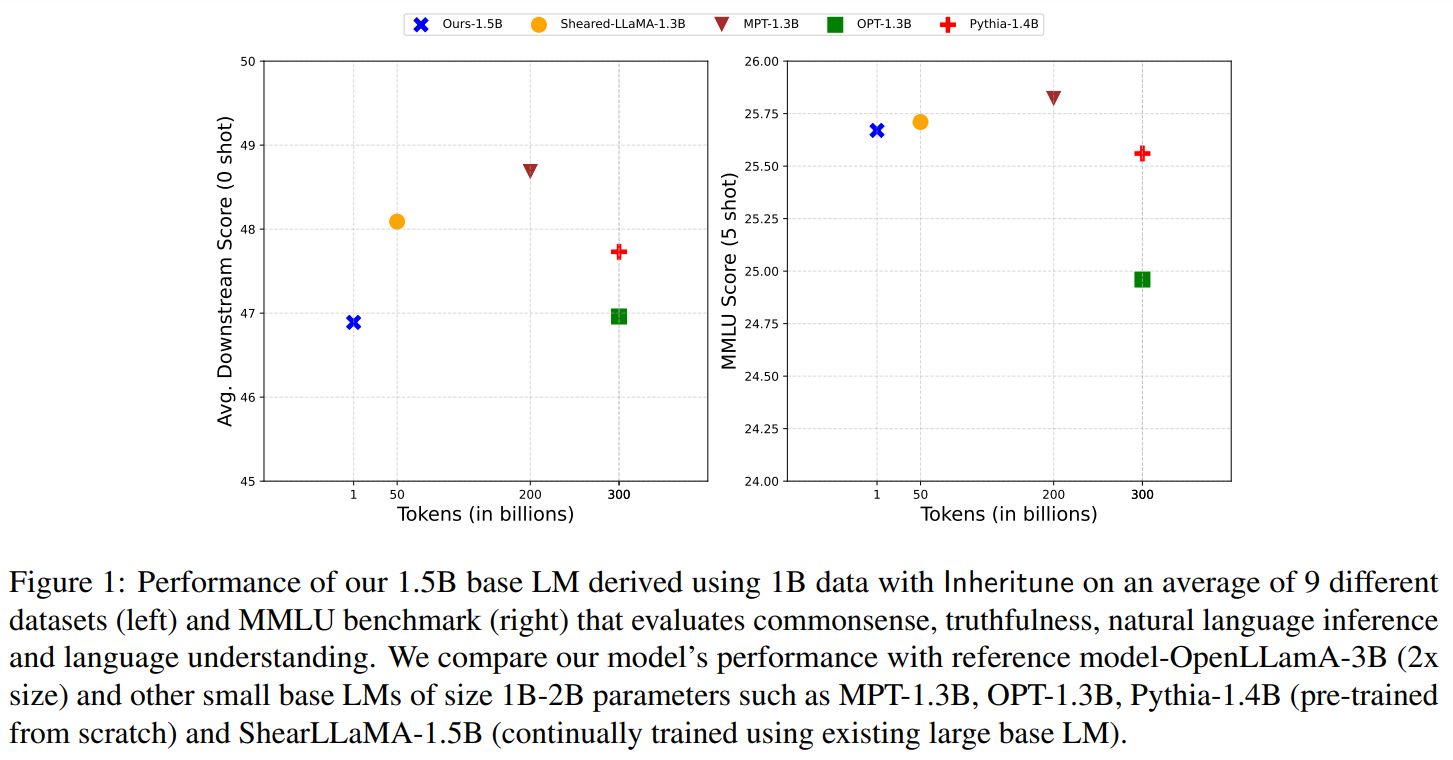
Researchers from UT Austin have developed “Inheritune,” a method to distinguish smaller base LMs from larger ones. They inherit a few transformer blocks from a larger LM and then train the smaller model on a tiny fraction (0.1%) of the original pretraining data. This approach efficiently creates LMs with 1.5 billion parameters using just 1 billion tokens, leveraging a single GPU in under 12 hours. Despite using significantly less data, the resulting models perform comparably to publicly available LMs trained on larger datasets, demonstrating efficacy across various settings.
Previous approaches to training small-base LMs involve extensive training from scratch with trillions of tokens or utilizing high-quality synthetic data. For instance, tinyllama-1B is trained from scratch with 3 trillion tokens over 90 days. In contrast, the Inheritune, efficiently trains small base LMs by inheriting transformer blocks from larger models and training on a small subset of data, achieving comparable performance with significantly fewer computational resources. While model compression techniques have been successful in other domains, such as neural networks, they have yet to be as effective in the complex functions of large LMs.
In the Inheritune approach, a small base LM is crafted by inheriting a fraction of pre-training data and a few layers from an existing large LM. Firstly, the first n layers of the reference model are inherited, initializing the target model. Then, the target model is trained on the available subset of training data for a specified number of epochs. In the experiments, the researchers use a 1 billion token subset of the Redpajama v1 dataset to train a 1.5 billion parameter LM, achieving competitive performance compared to scratch-trained and derived LMs. The researchers evaluate the approach using various baseline models, primarily considering their pre-training data quality for fair comparison.
Inheritance enables the extraction of smaller target LMs without sacrificing performance, showcasing comparable zero-shot performance on relevant downstream tasks. Moreover, these LMs outperform similar-sized models trained from scratch, surpassing them after fewer training steps. Experimentation with GPT2-medium models demonstrates that initialization with Inheritune, particularly with attention and MLP weights, yields superior convergence speed and final validation loss performance. Surprisingly, initializing either attention or MLP weights produces similar improvements in convergence speed and validation loss.
Also, Limitations of the Inheritune method include its inability to modify the architectural design beyond changing the number of transformer blocks, potentially limiting flexibility in customizing hidden sizes and attention heads. Sensitivity to the quality of the training dataset is another concern due to its small size. Additionally, selecting blocks to retain, dataset curation, and hyperparameter tuning still need to explore avenues for improvement. Nevertheless, the study concludes that Inheritune effectively pre-trains small base language models with minimal data and computational resources, offering a straightforward approach to model reduction from large reference models.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
For Content Partnership, Please Fill Out This Form Here..
The post ‘Inheritune’ by UT Austin Assists Efficient Language Model Training: Leveraging Inheritance and Reduced Data for Comparable Performance appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]