


Vision-language models in AI are designed to understand and process information from visual and textual inputs, simulating the human ability to perceive and interpret the world around us. The intersection of vision and language understanding is crucial for various applications, from automated image captioning to complex scene understanding and interaction.
The challenge at hand, however, is the development of models that can effectively integrate and interpret visual and linguistic information, which remains a complex problem. This challenge is compounded by the need for models to understand individual elements within an image or text and grasp the nuanced interplay between them.
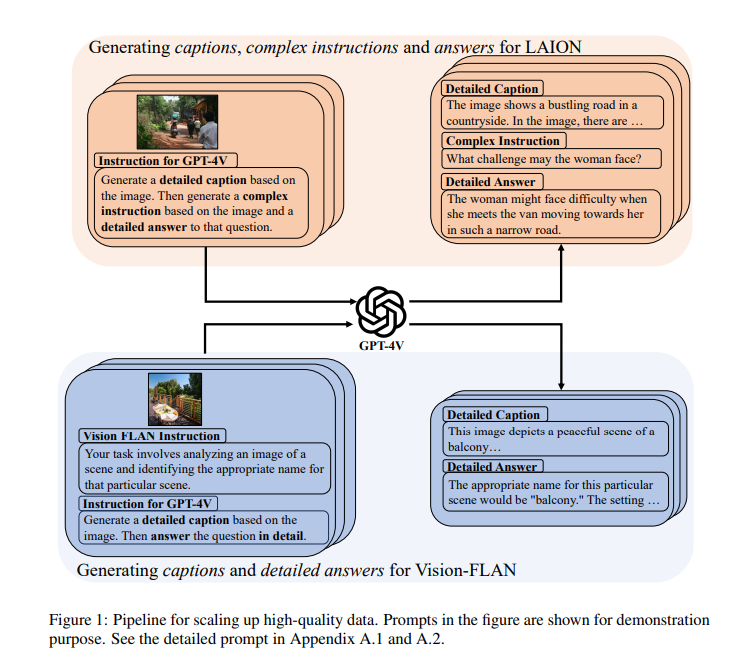
Existing methods for image-text alignment in language models use caption data. Still, the captions often need to be longer and more coarse-grained, leading to noisy signals and hindering alignment. The current scale of aligned data is limited, making it challenging to learn long-tailed visual knowledge. Expanding the quantity of aligned data from diverse sources is crucial for a nuanced understanding of less internationally renowned visual concepts. Visual instruction datasets focus on simple questions and improving fundamental abilities rather than complex reasoning. The answers in these datasets often need to be longer, uninformative, and require polishing or regeneration.
A team of researchers from the Shenzhen Research Institute of Big Data and the Chinese University of Hong Kong presents a novel method for enhancing vision-language models. Their approach, A Lite Language and Vision Assistant (ALLaVA) leverages synthetic data generated by GPT-4V to train a light version of large vision-language models (LVLMs). This method aims to provide a more resource-efficient solution without compromising on performance.
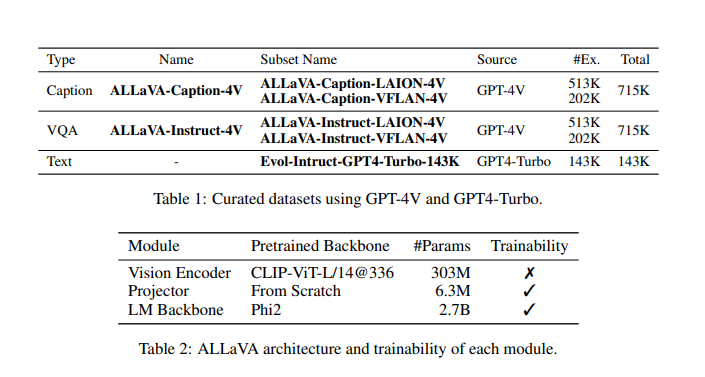
Leveraging GPT-4V, ALLaVA synthesizes data through a captioning-then-QA methodology, focusing on images from Vision-FLAN and LAION sources. This process involves detailed captioning, generating complex questions for rigorous reasoning, and providing comprehensive answers. Ethical guidelines are strictly adhered to, avoiding biased or inappropriate content. The outcome includes two expansive synthetic datasets: ALLaVA-Caption and ALLaVA-Instruct, consisting of captions, visual questions and answers (VQAs), and high-quality instructions. The architecture employs CLIP-ViT-L/14@336 for vision encoding and Phi2 2.7B for the language model backbone, ensuring robust performance across various benchmarks.
The model achieves competitive performance on 12 benchmarks up to 3B LVLMs. It can achieve comparable performance with much larger models, highlighting its efficiency and effectiveness. Ablation analysis shows that training the model with ALLaVA-Caption-4V and ALLaVA-Instruct-4V datasets significantly improves performance on benchmarks. The Vision-FLAN questions are relatively simple, focusing on enhancing fundamental abilities rather than complex reasoning. The success of ALLaVA underscores the potential of using high-quality synthetic data to train more efficient and effective vision-language models, making advanced AI technologies more accessible.

In conclusion, the model developed in the research, ALLaVA, represents a significant step forward in developing light vision-language models. By utilizing synthetic data generated by advanced language models, the research team has demonstrated the feasibility of creating efficient yet powerful models capable of understanding complex multimodal inputs. This approach addresses the challenge of resource-intensive training and opens new avenues for applying vision-language models in real-world scenarios.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Improving LVLM Efficiency: ALLaVA’s Synthetic Dataset and Competitive Performance appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]