


Natural Language Processing (NLP) has seen transformative advancements over the past few years, largely driven by the developing of sophisticated language models like transformers. Among these advancements, Retrieval-Augmented Generation (RAG) stands out as a cutting-edge technique that significantly enhances the capabilities of language models. RAG integrates retrieval mechanisms with generative models to create customizable, highly efficient, and accurate language models. Let’s study how RAG helps transformers build customizable LLMs and their underlying mechanisms, benefits, and applications.
Understanding Transformers and Their Limitations
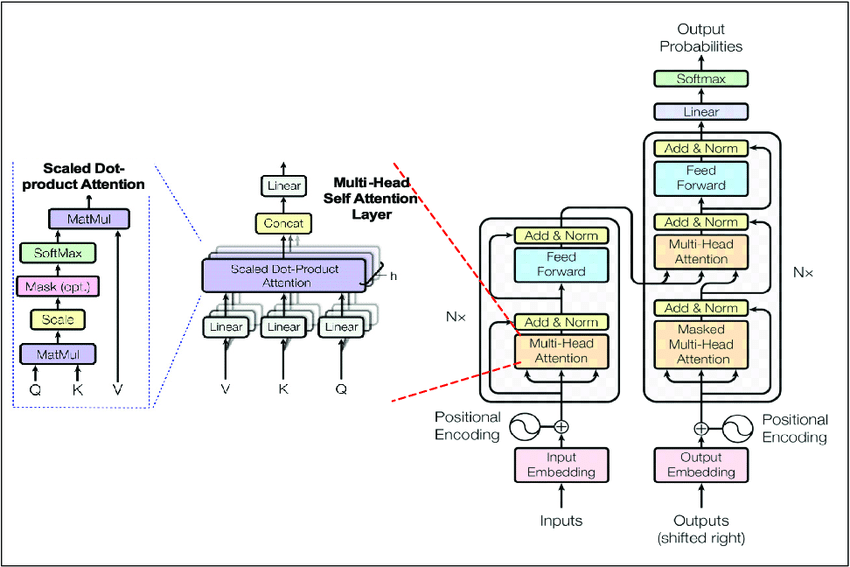
Transformers have revolutionized NLP with their ability to process and generate human-like text. The transformer architecture employs self-attention mechanisms to handle dependencies in sequences, making it highly effective for tasks such as translation, summarization, and text generation. However, transformers face limitations:
- Memory Constraints: Transformers have a fixed context window, typically 512 to 2048 tokens, which limits their ability to leverage large external knowledge bases directly.
- Static Knowledge: Once trained, transformers cannot dynamically update their knowledge base without retraining.
- Resource Intensity: Training large language models requires substantial computational resources, making it impractical for many users to customize models frequently.
Retrieval-Augmented Generation (RAG)
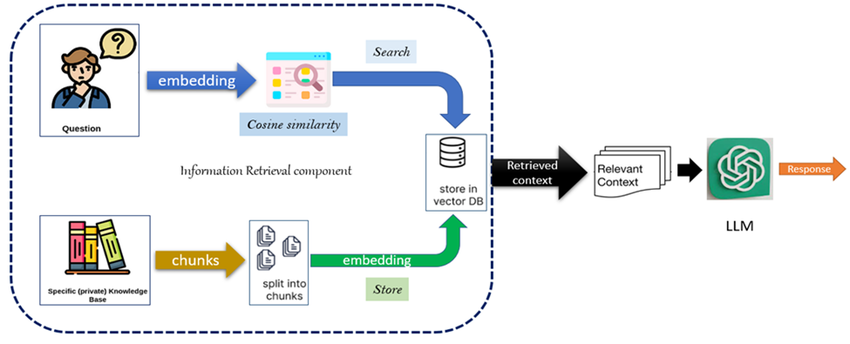
RAG addresses these limitations by combining the strengths of retrieval systems and generative models. Developed by Facebook AI, RAG leverages an external retrieval mechanism to fetch relevant information from a large corpus, which is then used to augment the generative process. This approach allows language models to access and utilize vast amounts of information beyond their fixed context window, enabling more accurate and contextually relevant responses.
How RAG Works
RAG operates in two primary phases: retrieval and generation.
- Retrieval Phase:
- Query Generation: Given an input, the model generates a query to retrieve relevant documents from an external corpus.
- Document Retrieval: The query is used to search a pre-indexed corpus, retrieving a set of relevant documents. This corpus can be as large as millions of records, providing a rich source of information.
- Generation Phase:
- Contextual Fusion: The retrieved documents are combined with the original input to form a more comprehensive context.
- Response Generation: The generative model (typically a transformer) uses this enriched context to generate a response, ensuring the output is relevant and informed by up-to-date information.
This dual-phase approach enables RAG to incorporate external knowledge dynamically, enhancing the model’s ability to handle complex queries & provide more accurate answers.
Benefits of RAG in Customizable LLMs
- Enhanced Accuracy and Relevance: By incorporating external documents into the generative process, RAG ensures that responses are based on the latest and most relevant information, improving the accuracy and relevance of the output.
- Dynamic Knowledge Integration: RAG allows models to access and utilize updated information without retraining, making it ideal for applications requiring real-time knowledge updates.
- Resource Efficiency: Instead of retraining large models, RAG enables customization by updating the retrieval corpus. This reduces the computational resources required for model customization.
- Scalability: RAG’s architecture can scale to handle vast amounts of data, making it suitable for enterprises and applications with extensive information needs.
- Flexibility: Users can tailor the retrieval corpus to specific domains or applications, enhancing the model’s performance in niche areas without extensive retraining.
Applications of RAG
RAG’s versatile framework opens up a wide array of applications across different industries:
- Customer Support: RAG can be used to create dynamic chatbots that access real-time information to provide accurate and up-to-date responses to customer queries.
- Healthcare: In medical diagnostics and information retrieval, RAG can assist by accessing the latest research and clinical guidelines to support healthcare professionals.
- Finance: RAG can help financial analysts by retrieving and synthesizing information from various financial reports and news articles to provide comprehensive market insights.
- Education: RAG-powered educational tools can offer personalized learning experiences by retrieving relevant study materials and resources tailored to individual students’ needs.
- Legal Research: Lawyers and researchers can use RAG to quickly access pertinent legal documents, case laws, and statutes, enhancing their research efficiency.
Conclusion
Retrieval-augmented generation (RAG) seamlessly integrates retrieval mechanisms with generative models, addressing the limitations of traditional transformers offering enhanced accuracy, dynamic knowledge integration, and resource efficiency. Its applications across various industries highlight its potential to revolutionize how to interact with and utilize language models. As the technology evolves, RAG is poised to become a cornerstone in developing next-generation NLP systems.
Sources
- https://arxiv.org/abs/1706.03762
- https://arxiv.org/abs/2005.11401
- https://ai.facebook.com/blog/retrieval-augmented-generation
The post How RAG helps Transformers to build customizable Large Language Models: A Comprehensive Guide appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]