


Large language models (LLMs) stand out for their astonishing ability to mimic human language. These models, pivotal in advancements across machine translation, summarization, and conversational AI, thrive on vast datasets and equally enormous computational power. The scalability of such models has been bottlenecked by the sheer computational demand, making training models with hundreds of billions of parameters a formidable challenge.
MegaScale is a collaboration between ByteDance and Peking University, enabling the training of LLMs on a previously unattainable scale. MegaScale’s genesis is rooted in the recognition that training LLMs at scale is not merely a question of harnessing more computational power but optimizing how that power is utilized. The system is designed from the ground up to address the dual challenges of efficiency and stability that have hampered previous efforts to scale up LLM training. By integrating innovative techniques across the model architecture, data pipeline, and network performance, MegaScale ensures that every bit of computational power contributes to more efficient and stable training.

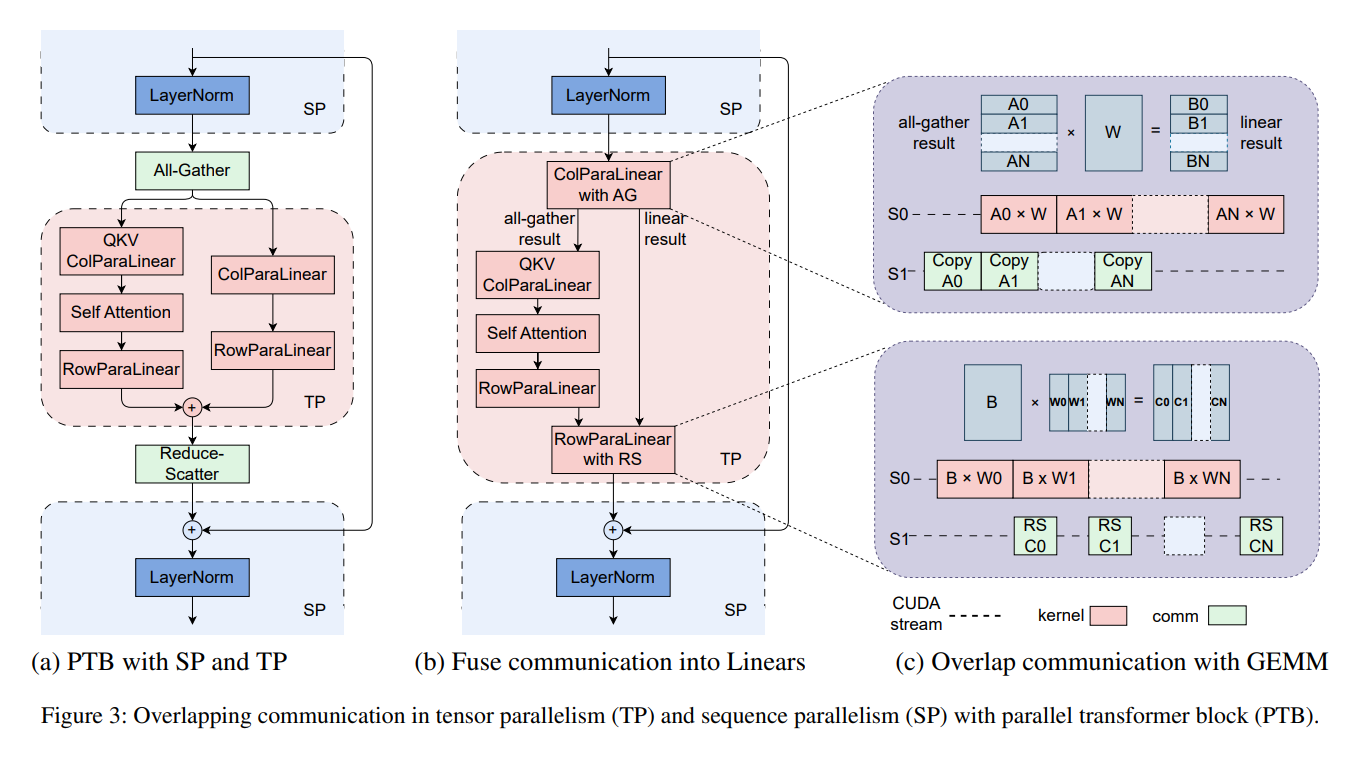
MegaScale’s methodology is a suite of optimization techniques tailored to the unique demands of LLM training. The system employs parallel transformer blocks and sliding window attention mechanisms to reduce computational overhead, while a sophisticated mix of data, pipeline, and tensor parallelism strategies optimizes resource utilization. These strategies are complemented by a custom network design that accelerates communication between the thousands of GPUs involved in the training process.
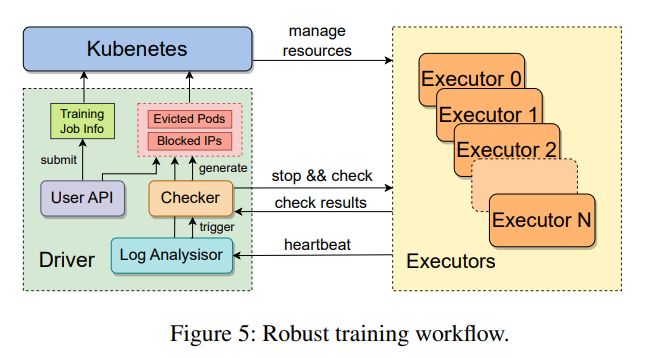
The system’s diagnostic and recovery capabilities further distinguish MegaScale. A robust set of tools monitors system components and events deep in the stack, allowing for the rapid identification and rectification of faults. This ensures high training efficiency and maintains this efficiency consistently over time, addressing one of the critical challenges in deploying LLMs at scale.
MegaScale’s impact is underscored by its performance in real-world applications. When tasked with training a 175B parameter LLM on 12,288 GPUs, MegaScale achieved a model FLOPs utilization (MFU) of 55.2%, significantly outpacing existing frameworks. This efficiency boost shortens training times and enhances the training process’s stability, ensuring that large-scale LLM training is both practical and sustainable.
In conclusion, MegaScale represents a significant moment in the training of LLMs, characterized by the following:
- A holistic approach to optimizing the LLM training process, from model architecture to network performance.
- The introduction of parallel transformer blocks and sliding window attention mechanisms, alongside a mix of parallelism strategies, to enhance computational efficiency.
- A custom network design and a robust diagnostic and recovery system ensure high training efficiency and stability.
- Demonstrated superiority in real-world applications, achieving unprecedented MFU and significantly improving the performance of existing training frameworks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post How Does Machine Learning Scale to New Peaks? This AI Paper from ByteDance Introduces MegaScale: Revolutionizing Large Language Model Training with Over 10,000 GPUs appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]