


The exploration of aligning large language models (LLMs) with human values and knowledge has taken a significant leap forward with innovative approaches that challenge traditional alignment methods. Traditional alignment techniques, heavily reliant on labeled data, face a bottleneck due to the necessity of domain expertise and the ever-increasing breadth of questions these models can tackle. As models evolve, surpassing even expert knowledge, the reliance on labeled data becomes increasingly impractical, highlighting the need for scalable oversight mechanisms that can adapt alongside these advancements.
A novel paradigm emerges from utilizing less capable models to guide the alignment of their more advanced counterparts. This method leverages a fundamental insight: critiquing or identifying the correct answer is often more straightforward than generating it. Debate, as proposed by Irving et al., emerges as a powerful tool in this context, providing a framework where a human or a weaker model can evaluate the accuracy of answers through adversarial critiques generated within the debate.

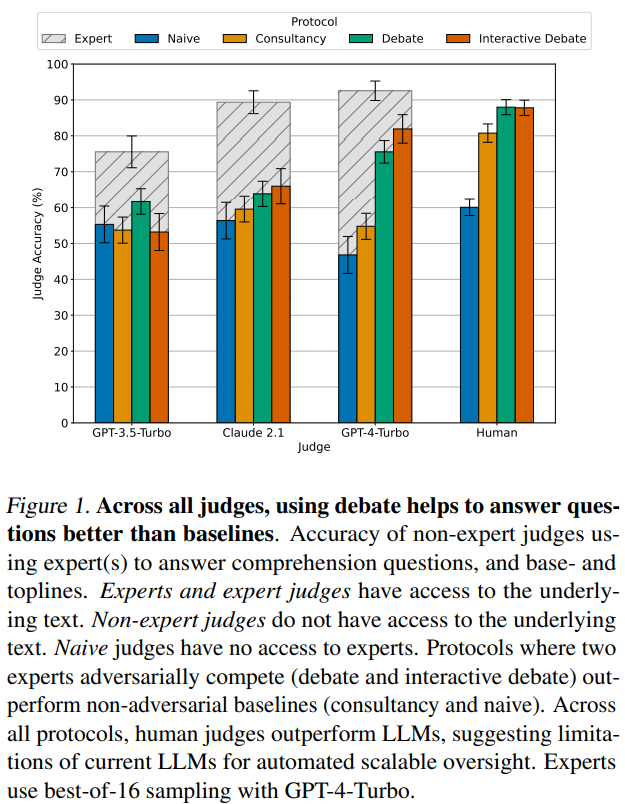
The research delves into the efficacy of debates in assisting “weaker” judges, who lack access to comprehensive background information, to evaluate “stronger” models. Through information-asymmetric debates in a reading comprehension task, the study illustrates how debates between experts, equipped with a quote verification tool, enable judges to discern the correct answers without direct access to the source material. This setup, as shown in Figure 2, focuses on the dynamics between debaters and judges and highlights a crucial aspect of scalable oversight: non-experts’ ability to extract the truth from expert discussions.
Debate protocols, including standard debates and interactive debates, alongside a consultancy baseline for comparison, form the core of the experimental setup. These protocols are meticulously designed to test the hypothesis under various conditions, including different numbers of debate rounds and word limits, ensuring a controlled environment for evaluating the models’ persuasiveness and accuracy.
The study employs a range of large language models as participants in these debates, including versions of GPT and Claude models, fine-tuned through reinforcement learning and Constitutional AI. The models undergo optimization for persuasiveness using inference-time methods, aiming to enhance their ability to argue convincingly for the correct answers. This optimization process, including techniques like best-of-N sampling and critique-and-refinement, is critical for assessing the models’ effectiveness in influencing judges’ decisions.
A significant portion of the research is dedicated to evaluating these protocols through the lens of both human and LLM judges, comparing the outcomes against the consultancy baseline. The findings reveal a notable improvement in judges’ ability to identify the truth in debates, with persuasive models leading to higher accuracy rates. This indicates that optimizing debaters for persuasiveness can indeed result in more truthful outcomes.
Moreover, the study extends its analysis to human judges, demonstrating their well-calibrated judgment and lower error rates when participating in debates. This human element underscores the potential of debate as a mechanism not only for model alignment but also for enhancing human decision-making in the absence of complete information.
In conclusion, the research presents a compelling case for debate as a scalable oversight mechanism capable of eliciting more truthful answers from LLMs and supporting human judgment. By enabling non-experts to discern truth through expert debates, the study showcases a promising avenue for future research in model alignment. The limitations highlighted, including the reliance on access to verified evidence and the potential challenges with models of differing reasoning abilities, pave the way for further exploration. This work not only contributes to the ongoing discourse on aligning LLMs with human values but also opens new pathways for augmenting human judgment and facilitating the development of trustworthy AI systems.
Through a comprehensive examination of debate protocols, optimization techniques, and the impact on both LLM and human judges, this study illuminates the potential of debate to foster a more truthful, persuasive, and ultimately trustworthy generation of language models. As we venture into an era where AI’s capabilities continue to expand, the principles of debate and persuasion stand as beacons guiding the path toward alignment, accountability, and enhanced human-AI collaboration.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Harnessing Persuasion in AI: A Leap Towards Trustworthy Language Models appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]