


Integrating domain-specific languages (DSL) into large vision-language models (LVLMs) heralds a transformative leap toward refining multimodal reasoning capabilities. While commendable for their ingenuity, traditional approaches often grapple with the nuanced complexities inherent in professional and intricate domains. The essence of multimodal reasoning lies in its ability to marry visual intuition with the precision of textual representations, thereby enabling a more nuanced understanding and interaction with the digital world.
The research pivots on a nuanced problem: the harmonious integration of disparate reasoning mechanisms stemming from visual and DSL representations. This integration is not merely a technical endeavor but a critical step towards unlocking a new realm of possibilities for complex reasoning tasks. Despite its merits, the conventional Chain-of-Thought (CoT) method reveals limitations when faced with the task of seamlessly merging these two distinct streams of reasoning. The inconsistency in reasoning processes not only diminishes the efficacy of the models but also highlights the need for a more sophisticated approach to leverage the strengths of both modalities.
Researchers from The University of Hong Kong and Tencent AI Lab introduce the Bi-Modal Behavioral Alignment (BBA) method, a novel prompting strategy meticulously designed to bridge the gap between visual and DSL representations. This method ingeniously commences by prompting LVLMs to generate distinct reasoning chains for each modality. It then embarks on meticulously aligning these chains by identifying and reconciling discrepancies, ensuring a cohesive integration. This approach is not merely a technical workaround but a strategic alignment that preserves the integrity and strengths of each representation, setting the stage for a more robust and accurate reasoning process.

BBA employs a late fusion strategy that maintains the unique advantages of direct vision input and DSL representation. This strategic choice is pivotal, especially in contexts where the precision of DSLs and the intuitive grasp of visual cues are equally indispensable. By turning inconsistencies across modalities into a beneficial signal, BBA identifies and emphasizes critical steps within the reasoning process, enhancing the model’s ability to navigate complex reasoning tasks with unprecedented precision.
BBA demonstrates remarkable improvements, evaluated across a spectrum of multimodal reasoning tasks, including geometry problem solving, chess positional advantage prediction, and molecular property prediction. For instance, in geometry problem solving, the method achieves a significant leap in performance, showcasing not only the versatility of BBA but also its capacity to adapt and excel across diverse domains. This empirical evidence, bolstered by rigorous comparative analysis, reaffirms the effectiveness of BBA in harnessing the synergies between visual and DSL representations.
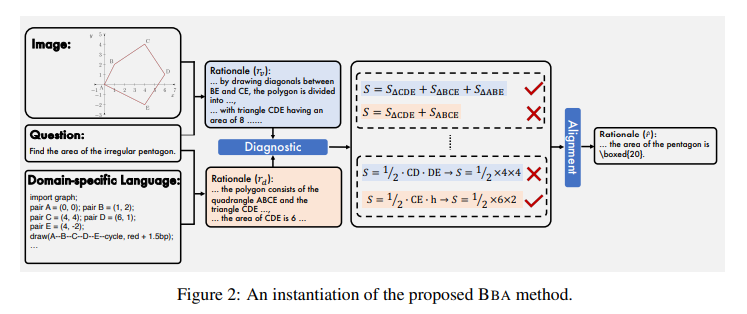
The research is at the intersection of DSL and LVLMs but is also a beacon for future explorations in multimodal reasoning. By addressing the fundamental challenges of integrating disparate reasoning mechanisms, BBA sets a new benchmark for accuracy and efficiency in complex reasoning tasks. The implications of this research extend beyond the immediate gains in performance, opening avenues for further exploration and refinement in artificial intelligence.
In conclusion, the journey of BBA from conception to realization embodies the relentless pursuit of excellence in the face of complex challenges. The convergence of vision and language, mediated through the prism of DSL, not only enriches our understanding of multimodal reasoning but also paves the way for a future where AI’s potential is bound only by the limits of our imagination. BBA emerges as a method and a milestone in the ongoing quest to decipher the intricate tapestry of human cognition through the lens of artificial intelligence.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Harmonizing Vision and Language: The Advent of Bi-Modal Behavioral Alignment (BBA) in Enhancing Multimodal Reasoning appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #Technology #Uncategorized [Source: AI Techpark]