


Detecting personally identifiable information PII in documents involves navigating various regulations, such as the EU’s General Data Protection Regulation (GDPR) and various U.S. financial data protection laws. These regulations mandate the secure handling of sensitive data, including customer identifiers, financial records, and other personal information. The diversity of data formats and the specific requirements of different domains necessitate a tailored approach to PII detection, which is where Gretel’s synthetic dataset comes into play.
Empowering PII Detection with Domain-Specific Datasets
Every organization has unique data formats and domain-specific requirements that may need to be fully captured by existing Named Entity Recognition (NER) models or sample datasets. Gretel’s Navigator tool allows developers to create customized synthetic datasets tailored to their needs. This approach significantly reduces the time & cost of traditional manual labeling techniques. By leveraging Gretel Navigator, developers can rapidly create large-scale, diverse, privacy-preserving datasets that accurately reflect the characteristics and challenges of their domain, ensuring that PII detection models are well-prepared for real-world scenarios and unique document types. One such dataset by Gretel is its multilingual Financial Document Dataset, released on the  platform this week.
platform this week.
Key Features of the Synthetic Financial Document Dataset
- Extensive Records: 55,940 records were partitioned into 50,776 training samples and 5,164 test samples.
- Coverage of Financial Document Formats: Includes 100 distinct financial document formats with 20 specific subtypes for each format.
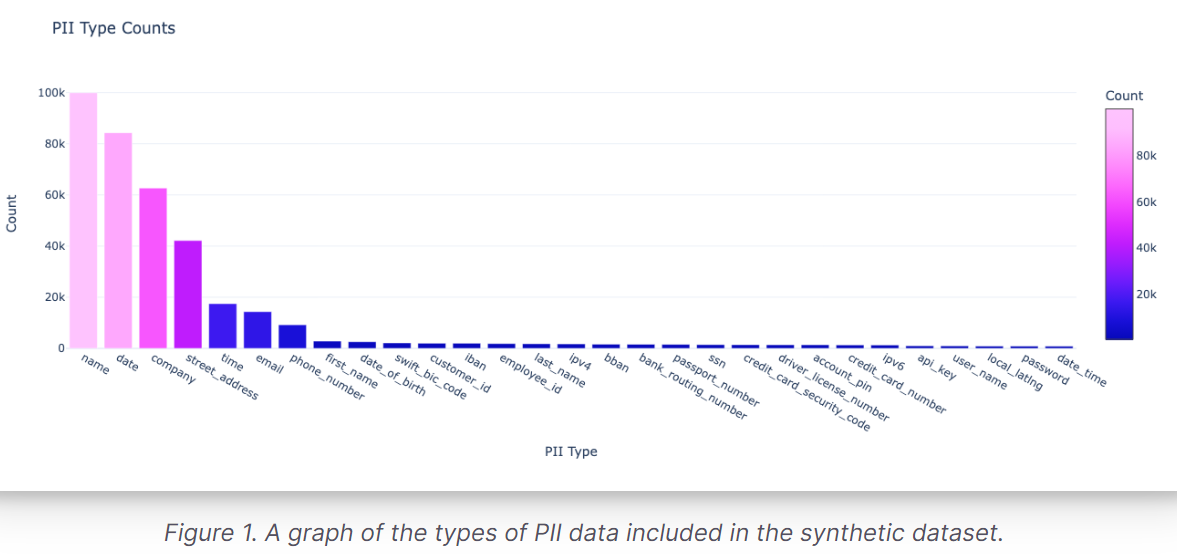
- Synthetic PII: Contains 29 distinct PII types, aligned with Python Faker library generators for easy detection and replacement.
- Full-Length Documents: The average length of documents is 1,357 characters.
- Multilingual Support: Supports English, Spanish, Swedish, German, Italian, Dutch, and French.
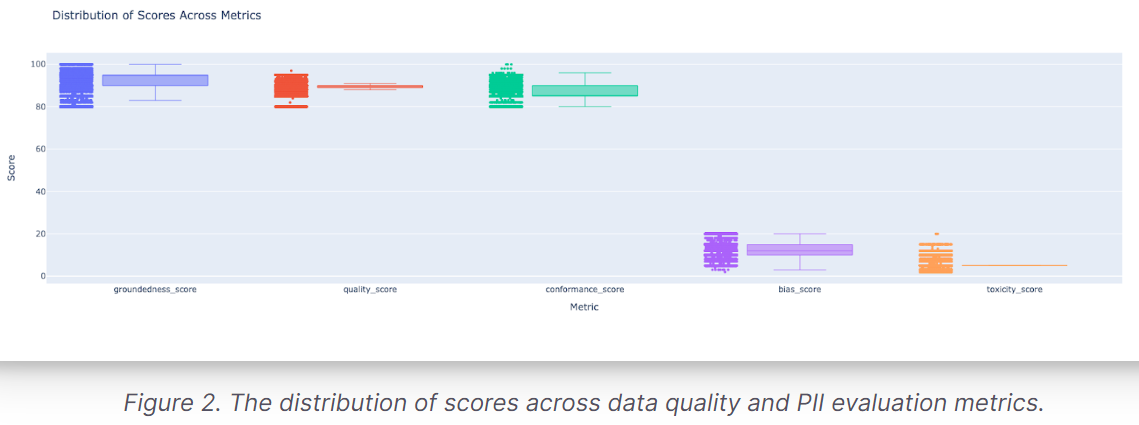
- Quality Assurance: The LLM-as-a-Judge technique with the Mistral-7B language model is used to ensure data quality and evaluate conformance, quality, toxicity, bias, and groundedness.
Use Cases of the Synthetic Financial Document Dataset
- Training NER Models: Detect and label PII in various domains.
- Testing PII Scanning Systems: Evaluate PII scanning systems on real, full-length documents unique to different domains.
- Evaluating De-identification Systems: Assess the performance of de-identification systems on realistic documents containing PII.
- Developing Data Privacy Solutions: Create and test data privacy solutions for the financial industry.
Quality Assessment and Usage
The quality of this dataset’s synthetic PII and documents is ensured through the LLM-as-a-Judge technique using the Mistral-7B language model. Each generated record is evaluated based on several criteria: conformance, quality, toxicity, bias, and groundedness. Records with high toxicity or bias scores or low groundedness, quality, or conformance scores are removed to maintain the dataset’s integrity. This rigorous quality assessment ensures the dataset is reliable and suitable for training robust PII detection models.
Supporting the Open Data Community
Gretel’s commitment to promoting open data and fostering collaboration within the AI community is evident in the release of this dataset. Gretel aims to accelerate the development of more accurate, unbiased, and trustworthy AI systems by sharing high-quality, diverse, and ethically sourced datasets. The synthetic financial document dataset is just one example of this commitment, providing a valuable resource for developers and researchers to build robust PII detection solutions.
Conclusion
Gretel’s synthetic financial document dataset represents an important innovation in PII detection. Gretel empowers AI developers to build more effective and domain-specific PII detection systems by providing a comprehensive and customizable dataset. This initiative addresses the technical challenges of PII detection and promotes data privacy and compliance across various industries. Resources like Gretel’s dataset will ensure sensitive data is handled securely and responsibly as AI evolves.
Sources
- https://gretel.ai/blog/gretel-unlocks-pii-detection-with-synthetic-financial-document-dataset
- https://huggingface.co/datasets/gretelai/synthetic_pii_finance_multilingual
- https://www.linkedin.com/feed/update/urn:li:activity:7206723643932868608/
The post Gretel AI Releases a New Multilingual Synthetic Financial Dataset on HuggingFace 🤗 for AI Developers Tackling Personally Identifiable Information PII Detection appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LargeLanguageModel #MachineLearning #NewReleases #Staff #TechNews #Technology [Source: AI Techpark]