
Many people with questions about grammar turn to Google Search for guidance. While existing features, such as “Did you mean”, already handle simple typo corrections, more complex grammatical error correction (GEC) is beyond their scope. What makes the development of new Google Search features challenging is that they must have high precision and recall while outputting results quickly.
The conventional approach to GEC is to treat it as a translation problem and use autoregressive Transformer models to decode the response token-by-token, conditioning on the previously generated tokens. However, although Transformer models have proven to be effective at GEC, they aren’t particularly efficient because the generation cannot be parallelized due to autoregressive decoding. Often, only a few modifications are needed to make the input text grammatically correct, so another possible solution is to treat GEC as a text editing problem. If we could run the autoregressive decoder only to generate the modifications, that would substantially decrease the latency of the GEC model.
To this end, in “EdiT5: Semi-Autoregressive Text-Editing with T5 Warm-Start”, published at Findings of EMNLP 2022, we describe a novel text-editing model that is based on the T5 Transformer encoder-decoder architecture. EdiT5 powers the new Google Search grammar check feature that allows you to check if a phrase or sentence is grammatically correct and provides corrections when needed. Grammar check shows up when the phrase “grammar check” is included in a search query, and if the underlying model is confident about the correction. Additionally, it shows up for some queries that don’t contain the “grammar check” phrase when Search understands that is the likely intent.
 |
Model architecture
For low-latency applications at Google, Transformer models are typically run on TPUs. Due to their fast matrix multiplication units (MMUs), these devices are optimized for performing large matrix multiplications quickly, for example running a Transformer encoder on hundreds of tokens in only a few milliseconds. In contrast, Transformer decoding makes poor use of a TPU’s capabilities, because it forces it to process only one token at a time. This makes autoregressive decoding the most time-consuming part of a translation-based GEC model.
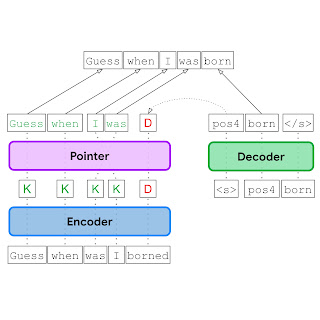
In the EdiT5 approach, we reduce the number of decoding steps by treating GEC as a text editing problem. The EdiT5 text-editing model is based on the T5 Transformer encoder-decoder architecture with a few crucial modifications. Given an input with grammatical errors, the EdiT5 model uses an encoder to determine which input tokens to keep or delete. The kept input tokens form a draft output, which is optionally reordered using a non-autoregressive pointer network. Finally, a decoder outputs the tokens that are missing from the draft, and uses a pointing mechanism to indicate where each new token should be placed to generate a grammatically correct output. The decoder is only run to produce tokens that were missing in the draft, and as a result, runs for much fewer steps than would be needed in the translation approach to GEC.
To further decrease the decoder latency, we reduce the decoder down to a single layer, and we compensate by increasing the size of the encoder. Overall, this decreases latency significantly because the extra work in the encoder is efficiently parallelized.
 |
| Given an input with grammatical errors (“Guess when was I borned”), the EdiT5 model uses an encoder to determine which input tokens to keep (K) or delete (D), a pointer network (pointer) to reorder kept tokens, and a decoder to insert any new tokens that are needed to generate a grammatically correct output. |
We applied the EdiT5 model to the public BEA grammatical error correction benchmark, comparing different model sizes. The experimental results show that an EdiT5 large model with 391M parameters yields a higher F0.5 score, which measures the accuracy of the corrections, while delivering a 9x speedup compared to a T5 base model with 248M parameters. The mean latency of the EdiT5 model was merely 4.1 milliseconds.
 |
| Performance of the T5 and EdiT5 models of various sizes on the public BEA GEC benchmark plotted against mean latency. Compared to T5, EdiT5 offers a better latency-F0.5 trade-off. Note that the x axis is logarithmic. |
Improved training data with large language models
Our earlier research, as well as the results above, show that model size plays a crucial role in generating accurate grammatical corrections. To combine the advantages of large language models (LLMs) and the low latency of EdiT5, we leverage a technique called hard distillation. First, we train a teacher LLM using similar datasets used for the Gboard grammar model. The teacher model is then used to generate training data for the student EdiT5 model.
Training sets for grammar models consist of ungrammatical source / grammatical target sentence pairs. Some of the training sets have noisy targets that contain grammatical errors, unnecessary paraphrasing, or unwanted artifacts. Therefore, we generate new pseudo-targets with the teacher model to get cleaner and more consistent training data. Then, we re-train the teacher model with the pseudo-targets using a technique called self-training. Finally, we found that when the source sentence contains many errors, the teacher sometimes corrects only part of the errors. Thus, we can further improve the quality of the pseudo-targets by feeding them to the teacher LLM for a second time, a technique called iterative refinement.
 |
| Steps for training a large teacher model for grammatical error correction (GEC). Self-training and iterative refinement remove unnecessary paraphrasing, artifacts, and grammatical errors appearing in the original targets. |
Putting it all together
Using the improved GEC data, we train two EdiT5-based models: a grammatical error correction model, and a grammaticality classifier. When the grammar check feature is used, we run the query first through the correction model, and then we check if the output is indeed correct with the classifier model. Only then do we surface the correction to the user.
The reason to have a separate classifier model is to more easily trade off between precision and recall. Additionally, for ambiguous or nonsensical queries to the model where the best correction is unclear, the classifier reduces the risk of serving erroneous or confusing corrections.
Conclusion
We have developed an efficient grammar correction model based on the state-of-the-art EdiT5 model architecture. This model allows users to check for the grammaticality of their queries in Google Search by including the “grammar check” phrase in the query.
Acknowledgements
We gratefully acknowledge the key contributions of the other team members, including Akash R, Aliaksei Severyn, Harsh Shah, Jonathan Mallinson, Mithun Kumar S R, Samer Hassan, Sebastian Krause, and Shikhar Thakur. We’d also like to thank Felix Stahlberg, Shankar Kumar, and Simon Tong for helpful discussions and pointers.
#DeepLearning #EMNLP #NLP #Search [Source: Google AI]