


Recent advancements in (self) supervised learning models have been driven by empirical scaling laws, where a model’s performance scales with its size. However, such scaling laws have been challenging to establish in reinforcement learning (RL). Unlike supervised learning, increasing the parameter count of an RL model often leads to decreased performance. This paper investigates the integration of Mixture-of-Expert (MoE) modules, particularly Soft MoEs, into value-based networks.
Deep Reinforcement Learning (RL) combines reinforcement learning with deep neural networks, creating a powerful tool in AI. It’s proven to be incredibly effective in solving tough problems, even surpassing human performance in some cases. This approach has gained a lot of attention across different fields, like gaming and robotics. Many studies have shown its success in tackling challenges that were previously thought to be impossible.
Even though Deep RL has achieved impressive results, how exactly deep neural networks work in RL is still unclear. These networks are crucial for helping agents in complex environments and improving their actions. But understanding how they’re designed and how they learn presents interesting puzzles for researchers. Recent studies have even found surprising things happening that go against what we usually see in supervised learning.
In this context, understanding the role of deep neural networks in Deep RL becomes imperative. This introductory section sets the stage for exploring the mysteries surrounding the design, learning dynamics, and peculiar behaviors of deep networks within the framework of Reinforcement Learning. Through a comprehensive examination, this study aims to shed light on the enigmatic interplay between deep learning and reinforcement learning, unraveling the complexities underlying the success of Deep RL agents.
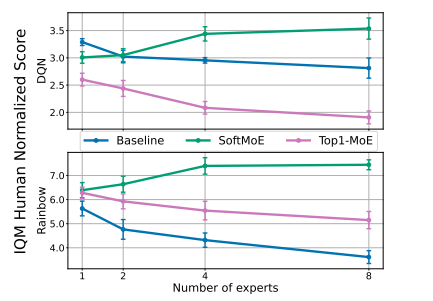
The above figure demonstrates the use of Mixture of Experts allows the performance of DQN (top) and Rainbow (bottom) to scale with an increased number of parameters. Mixture of Experts (MoEs) in neural networks selectively routes inputs to specialized components. While commonly used in transformer architectures for token inputs, the concept of tokens is not universally applicable in deep reinforcement learning networks, unlike in most supervised learning tasks.
Significant distinctions are observed between the baseline architecture and those incorporating Mixture of Experts (MoE) modules. In comparison to the baseline network, architectures with MoE modules demonstrate higher numerical ranks in empirical Neural Tangent Kernel (NTK) matrices and exhibit minimal dormant neurons and feature norms. These observations hint at the stabilizing influence of MoE modules on optimization dynamics, although direct causal links between improvements in these metrics and agent performance are not conclusively established.

Mixtures of Experts introduce a structured sparsity into neural networks, raising the question of whether the observed benefits stem solely from this sparsity rather than the MoE modules themselves. Our findings indicate that it is probably a combination of both factors. Figure 1 illustrates that in Rainbow, incorporating an MoE module with a single expert leads to statistically significant performance enhancements, while Figure 2 shows that reducing expert dimensionality can be done without compromising performance.
The results indicate the potential for Mixture of Experts (MoEs) to offer broader advantages in training deep RL agents. Moreover, these findings affirm the significant impact that architectural design decisions can exert on the overall performance of RL agents. It is hoped that these results will inspire further exploration by researchers into this relatively uncharted research direction.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Google DeepMind’s Latest Machine Learning Breakthrough Revolutionizes Reinforcement Learning with Mixture-of-Experts for Superior Model Scalability and Performance appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]