


Language models are the backbone of modern artificial intelligence systems, enabling machines to understand and generate human-like text. These models, which process and predict language, are critical for various applications, from automated translation services to interactive chatbots. However, developing these models presents significant challenges, primarily due to the computational and memory resources required for effective operation.
One major hurdle in language model development is balancing the complexity needed to handle intricate language tasks with the need for computational efficiency. As the demand for more sophisticated models grows, so does the requirement for more powerful and resource-intensive computing solutions. This balance is difficult to achieve when models are expected to process long text sequences, which can quickly exhaust available memory and processing power.
Transformer-based models have been at the forefront of addressing these challenges. These models utilize mechanisms that allow them to attend to different parts of the text to predict what comes next, making them highly effective for tasks involving long-range dependencies. However, their reliance on large-scale memory and computational resources often makes them impractical for extended sequences or devices with limited capabilities.
A research team from Google DeepMind has developed RecurrentGemma, a novel language model incorporating the Griffin architecture. This new model addresses the inefficiencies of traditional transformer models by combining linear recurrences with local attention mechanisms. The innovation lies in its ability to maintain high performance while reducing the memory footprint, which is crucial for efficiently processing lengthy text sequences.
RecurrentGemma stands out by compressing input sequences into a fixed-size state, avoiding the exponential growth in memory usage typical of transformers. The model’s architecture significantly reduces memory demands, enabling faster processing speeds without sacrificing accuracy. Performance metrics indicate that RecurrentGemma, with its 2 billion non-embedding parameters, matches or exceeds the benchmark results of its predecessors like Gemma-2B, even though it is trained on fewer data tokens, approximately 2 trillion compared to Gemma-2B’s 3 trillion.
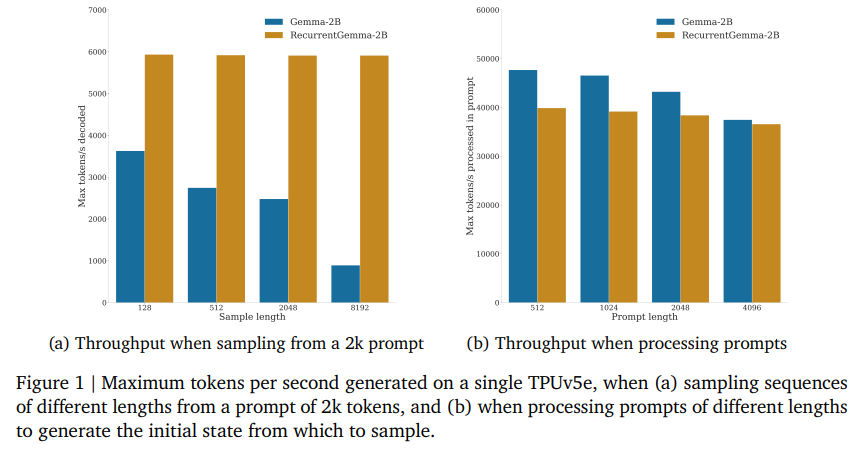
RecurrentGemma achieves these results while enhancing inference speeds. Benchmarks have shown that it can process sequences substantially faster than traditional models, with evaluations demonstrating throughput of up to 40,000 tokens per second on a single TPUv5e device. This capability is particularly notable during tasks that involve lengthy sequences where RecurrentGemma does not suffer from reduced throughput, unlike its transformer counterparts, whose performance degrades as the sequence length increases.
Research Snapshot

In conclusion, the research by Google DeepMind introduces RecurrentGemma, an innovative language model that addresses the critical balance between computational efficiency and model complexity. By implementing the Griffin architecture, which combines linear recurrences with local attention, RecurrentGemma significantly reduces memory usage while maintaining robust performance. It excels in processing long text sequences swiftly, achieving speeds up to 40,000 tokens per second. This breakthrough demonstrates that achieving state-of-the-art performance is possible without the extensive resource demands typically associated with advanced language models. This makes it ideal for use in various applications, particularly where resources are limited.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post Google DeepMind Releases RecurrentGemma: One of the Strongest 2B-Parameter Open Language Models Designed for Fast Inference on Long Qequences appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #NewReleases #Staff #TechNews #Technology [Source: AI Techpark]