


In the evolving landscape of artificial intelligence, vision-language models (VLMs) stand as a testament to the quest for machines that can interpret and understand the world like human perception. These models, which analyze visual content and textual descriptions together, have shown remarkable prowess in tasks ranging from image captioning to complex question answering. However, despite their advances, a significant hurdle still needs to be solved in enabling these models to reason with the depth and flexibility characteristic of human cognition. VLMs, for instance, have needed help to fully grasp and interpret charts, graphs, and diagrams, elements rich in information but challenging to decode.
Researchers have tirelessly explored methods to enhance these models’ interpretative and inferential capabilities. Previous strategies have primarily focused on improving the models’ ability to recognize and categorize visual elements. Yet, the leap from mere recognition to sophisticated reasoning, where a model sees, understands, and infers from visual data, has to be discovered. This gap significantly limits the potential applications of VLMs, especially in fields requiring nuanced interpretation of complex multimodal data.
A research team from Google Research has introduced an innovative method to bridge this gap by leveraging large language models (LLMs). Their approach focuses on transferring the advanced reasoning capabilities of LLMs to VLMs, thereby enhancing the latter’s ability to make sense of and reason about visual data, especially charts and diagrams. The cornerstone of their methodology is a comprehensive pre-training and fine-tuning process enriched by a synthetically generated dataset that is substantially larger than its predecessors.
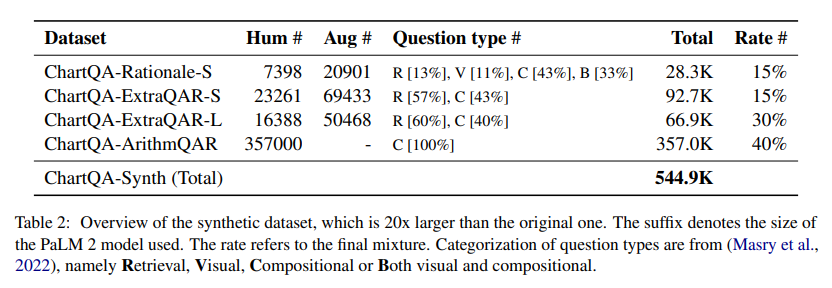
The methodology employs an enhanced chart-to-table translation task during the pre-training phase and constructs a dataset twenty times the size of the original training set. This expansive dataset enables the model to engage in complex reasoning and perform numerical operations with unprecedented accuracy. Synthetic data generation technique is pivotal in synthesizing reasoning traces that mimic human thought processes.
Key Achievements of the Research include:
- The introduction of ChartPaLI-5B, a model variant that sets a new standard in the domain of VLMs.
- Achieving state-of-the-art performance on the ChartQA benchmark, surpassing models with ten times more parameters.
- Demonstrating superior reasoning capabilities without needing an upstream OCR system, thereby maintaining constant inference time.
- ChartPaLI-5B outperforms the latest models in the field, including Gemini Ultra and GPT-4V, when further refined with a simple program-of-thought prompt.
The research presents compelling evidence of the efficacy of their method through its remarkable performance across multiple benchmarks. On the ChartQA benchmark, a tool designed to quantify a VLM’s ability to reason with complex chart data, ChartPaLI-5B achieved an impressive 77.28% accuracy, setting a new record in the process. The model demonstrated its robustness and versatility by excelling in related tasks.
This pioneering research not only underscores the potential of integrating the analytical strengths of LLMs into VLMs but also marks a significant stride toward realizing AI systems capable of multimodal reasoning that approaches human levels of complexity and subtlety. The approach opens new avenues for developing AI models that can navigate the nuanced interplay of visual and textual information, promising advancements in areas ranging from automated data analysis to interactive educational tools.
In conclusion, the ChartPaLI-5B in vision-language modeling is characterized by enhanced reasoning capabilities and superior performance on complex multimodal tasks. The research team has charted a path toward more intelligent, versatile, and capable AI systems by synthesizing the reasoning prowess of LLMs with the perceptive capabilities of VLMs. This fusion of visual understanding and advanced reasoning sets a new benchmark for VLM performance and expands the possibilities for AI applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
The post Google AI Research Introduces ChartPaLI-5B: A Groundbreaking Method for Elevating Vision-Language Models to New Heights of Multimodal Reasoning appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]