


Generative models of tabular data are key in Bayesian analysis, probabilistic machine learning, and fields like econometrics, healthcare, and systems biology. Researchers have developed methods to learn probabilistic models for such data automatically. To leverage these models for complex tasks, users must seamlessly integrate operations accessing data records and probabilistic models. This includes generating synthetic data with constraints, conditioning distributions on observed data, and performing database operations on combined tabular and model data. However, most probabilistic programming systems focus on model specification and parameter estimation, needing more support for intricate database queries that merge tabular data with generative models.
Researchers from MIT, Digital Garage, and Carnegie Mellon present GenSQL, a probabilistic programming system for querying generative models of database tables. GenSQL extends SQL with new primitives to enable complex Bayesian workflows. It integrates probabilistic models, which can be automatically learned or custom-designed, with tabular data for tasks like anomaly detection and synthetic data generation. GenSQL’s novel interface and soundness guarantees ensure accurate and efficient query execution. Benchmarks show GenSQL’s superior performance, offering up to a 6.8x speedup over competitors. The open-source implementation supports various probabilistic programming languages, proving its utility in real-world applications.
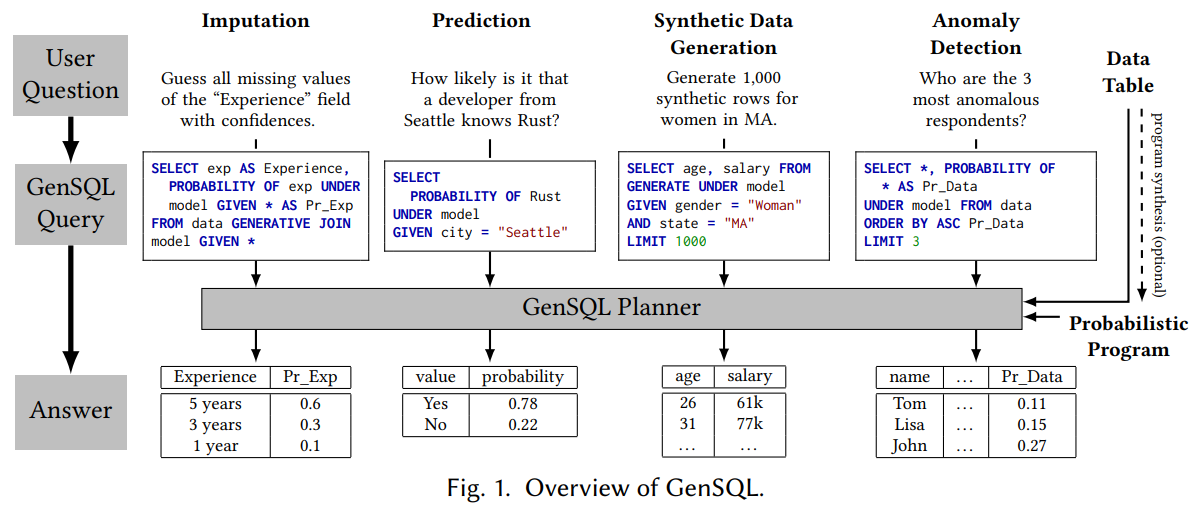
Probabilistic databases use efficient algorithms for inference queries on discrete distributions, integrating probabilities into relational systems for tasks like imputation and random data generation. GenSQL offers a formal system, denotational semantics, soundness guarantees, and a unified interface for probabilistic models. The semantics of probabilistic databases have been explored through various frameworks and formalizations. GenSQL leverages probabilistic program synthesis for powerful Bayesian workflows and supports models from different probabilistic programming languages. Unlike BayesDB, GenSQL provides novel semantic concepts, soundness theorems, and enhanced performance and expressiveness, enabling nested queries and combining results from multiple models.
GenSQL is a probabilistic extension of SQL designed for querying from probabilistic tabular data models. It includes constructs for traditional SQL operations and probabilistic models, with distinct names and types for columns and tables. The type system ensures well-typed expressions, handling continuous and discrete types, and includes special rules for events with zero probability. GenSQL’s semantics use measure theory for probabilistic aspects, offering compositional semantics for expressions. It features conditioning constructs, syntactic shortcuts, and special null-value treatment. GenSQL is ideal for generating synthetic data, querying probabilistic models, and handling complex conditional queries.
The evaluation of GenSQL, a Clojure-based probabilistic SQL extension, compares its performance against similar systems. Conducted on an Amazon EC2 C6a instance, the study benchmarks runtime and optimizations using probabilistic models generated via ClojureCat. GenSQL outperforms BayesDB significantly across ten benchmark queries, achieving speedups ranging from 1.7x to 6.8x due to its efficient ClojureCat backend and strategic optimizations like caching and exploiting column independence. Case studies illustrate its practical applications in anomaly detection in clinical trials and synthetic data generation for genetic experiments, demonstrating its effectiveness in complex data analysis and modeling scenarios.
In conclusion, GenSQL innovates probabilistic programming by specializing in tabular data applications, distinguishing itself from general-purpose PPLs in several key aspects. It facilitates multi-language workflows through its AMI, allowing seamless integration of models across different languages and backends. GenSQL also introduces a declarative querying approach, simplifying complex queries that combine probabilistic models with database operations. Moreover, it enables reusable performance optimizations akin to those in traditional DBMS, enhancing efficiency across diverse domains without requiring domain-specific optimizations. These innovations promise broader applications in synthetic data generation and modular query development, fostering efficient and scalable use of generative models in practical data analysis.
Check out the Paper, Blog, and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post GenSQL: A Generative AI System for Databases that Advances Probabilistic Programming for Integrated Tabular Data Analysis appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #GenerativeAI #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]