


The Galileo Luna represents a significant advancement in language model evaluation. It is specifically designed to address the prevalent issue of hallucinations in large language models (LLMs). Hallucinations, or instances where models generate information not grounded in the retrieved context, pose a significant challenge in deploying language models in industry applications. The Galileo Luna is a purpose-built evaluation foundation model (EFM) that ensures high accuracy, low latency, and cost efficiency in detecting and mitigating these hallucinations.
The Problem of Hallucinations in LLMs
Large language models have revolutionized natural language processing with their impressive ability to generate human-like text. However, their tendency to produce factually incorrect information (hallucinations) undermines their reliability, especially in critical applications such as customer support, legal advice, and biomedical research. Hallucinations can arise from various factors, including outdated knowledge bases, randomization in response generation, faulty training data, and the incorporation of new knowledge during fine-tuning.
Retrieval-augmented generation (RAG) systems have been developed to incorporate relevant external knowledge into the LLM’s responses to address these issues. Despite this, existing hallucination detection techniques often fail to balance accuracy, latency, and cost, making them less feasible for real-time, large-scale industry applications.
Luna: The Evaluation Foundation Model
Galileo Technologies has introduced Luna, a DeBERTa-large encoder fine-tuned to detect hallucinations in RAG settings. Luna stands out for its high accuracy, low cost, and millisecond-level inference speed. It surpasses existing models, including GPT-3.5, in both performance and efficiency.
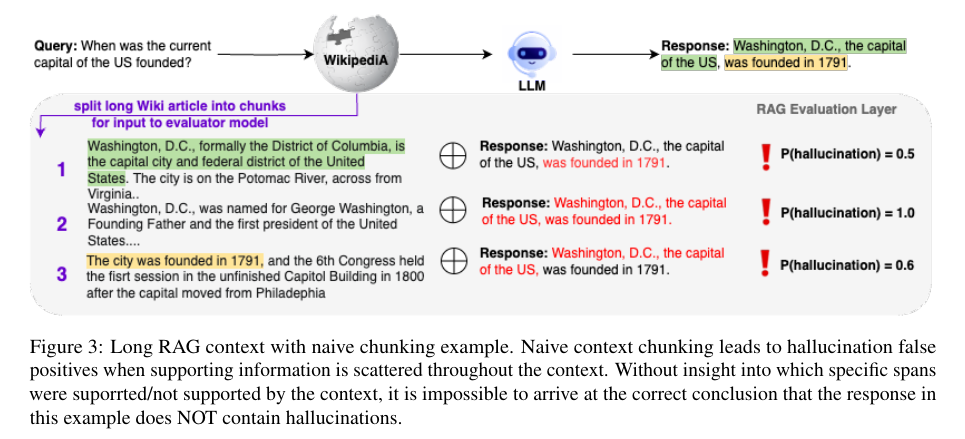
Luna’s architecture is built upon a 440-million parameter DeBERTa-large model, fine-tuned with real-world RAG data. This model is designed to generalize across multiple industry domains and handle long-context RAG inputs, making it an ideal solution for diverse applications. Its training involves a novel chunking approach that processes long context documents to minimize false positives in hallucination detection.
The 5 Breakthroughs in GenAI Evaluations with Galileo Luna:
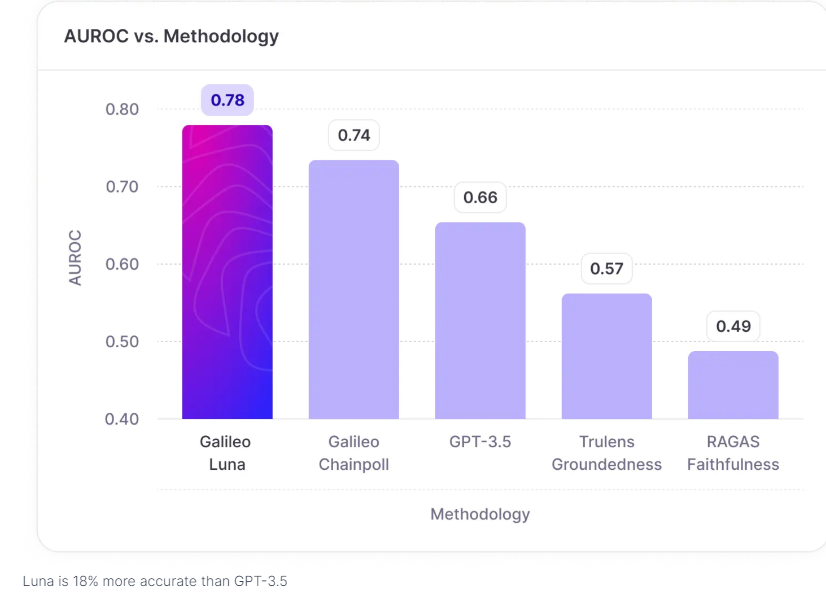
- Leading Evaluation Accuracy Benchmarks: Luna is 18% more accurate than GPT-3.5 in detecting hallucinations in RAG-based systems. This accuracy extends to other evaluation tasks, such as prompt injections and PII detection.
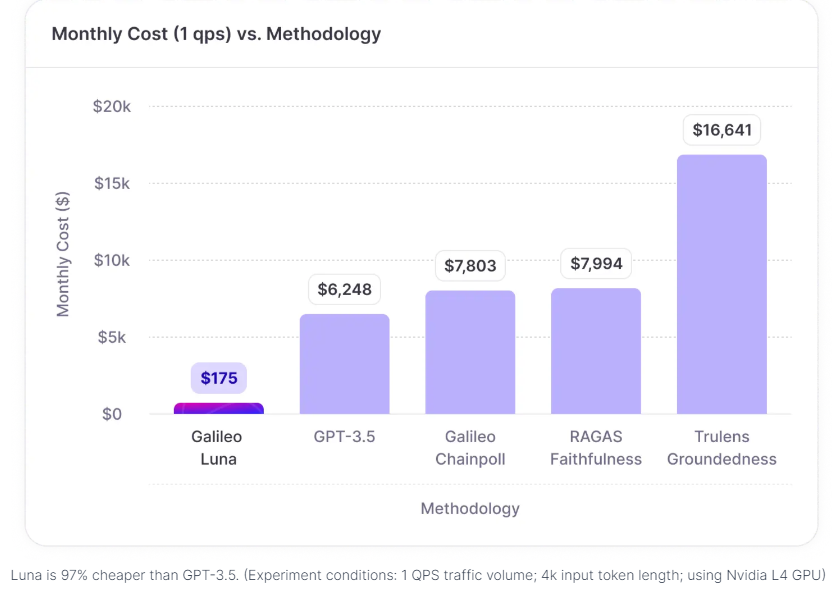
- Ultra Low-Cost Evaluation: Luna significantly reduces evaluation costs by 97% compared to GPT-3.5, making it a cost-effective solution for large-scale deployments.
- Ultra Low Latency Evaluation: Luna is 11 times faster than GPT-3.5, processing evaluations in milliseconds, ensuring a seamless and responsive user experience.
- Detect Hallucinations, Security, and Data Privacy Without Ground Truth: eliminates the need for costly and labor-intensive ground truth test sets by using pre-trained evaluation-specific datasets, allowing for immediate and effective evaluation.
- Built for Customizability: Luna can be quickly fine-tuned to meet specific industry needs, providing ultra-high accuracy custom evaluation models within minutes.
Performance and Cost Efficiency
Luna has demonstrated superior performance in extensive benchmarking against other models. Compared to GPT-3.5 and other commercial evaluation frameworks, it achieves a 97% reduction in cost and a 91% reduction in latency. These efficiencies are critical for large-scale deployment, where real-time response generation and cost management are paramount.
The model’s ability to process up to 16,000 tokens in milliseconds makes it suitable for real-time applications like customer support and interactive chatbots. Luna’s lightweight architecture allows it to be deployed on local GPUs, ensuring data privacy and security, a significant advantage over third-party API-based solutions.
Applications and Customizability
Luna is designed to be highly customizable, enabling fine-tuning to meet specific industry needs. For instance, in pharmaceutical applications, where hallucinations can have serious implications, Luna can be tailored to detect particular classes of hallucinations with over 95% accuracy. This flexibility ensures the model can be adapted to various domains, enhancing its utility and effectiveness.
Luna supports a range of evaluation tasks beyond hallucination detection, including context adherence, chunk utilization, context relevance, and security checks. Its multi-task training approach allows it to perform multiple evaluations with a single input, sharing insights across tasks for more robust and accurate results.
Conclusion
The introduction of Galileo Luna marks a significant milestone in developing evaluation models for large language systems. Its high accuracy, cost efficiency, and low latency make it a valuable tool for ensuring the reliability and trustworthiness of AI-driven applications. By addressing the critical issue of hallucinations in LLMs, Luna paves the way for more robust and dependable language models in various industry settings.
Check out the Paper and Blog. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post Galileo Introduces Luna: An Evaluation Foundation Model to Catch Language Model Hallucinations with High Accuracy and Low Cost appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #NewReleases #Staff #TechNews #Technology [Source: AI Techpark]